记一次协助本科实验室迁移物理服务器集群的经历
背景
实验室虚拟化资源的密集需求
本科实验室(下亦称“小组”)目前约有 25 名学生及 2 位指导老师,每年春季会组织集中招新,每年约招收 5-8 名不同方向的新生。小组平时主要以参加 CTF 比赛为主线,引导大家进行网络安全方面的学习和实践,同时也会承担一些工程项目,因此有一小部分可自行支配的资金。硬件条件方面,小组具备一块独立的办公区域,空调等设施齐全,甚至配有一张行军床。网络方面为千兆有线 & Wi-Fi 7 网络接入,互联网带宽为校园网提供,视情况最高可达 1000 Mbps,网络设备全部采用华为、锐捷等主流品牌,给日常实验提供有力的保障。氛围十分融洽,每周会组织一次技术 workshop ,知识库、Git 仓库等一直传承和更新,经常会有挑灯夜战的同学。以上是我在实验室期间的主观感受。

作为 2021 年加入小组的学生,我梳理了一下实验室的虚拟化资源的变迁:
2021年之前,小组有两台浪潮 NP5540 安装了 VMware Exsi,每台装有两颗 Xeon E5-2407 和 16GB 内存。这配置,甚至还不如 2021 年的笔记本。
2022 年,一名学长捐赠了一台戴尔 Precision T5600,装有两颗 Xeon E5-2660 和 32GB 内存。原本是跑的 ArchLinux ,镜像站的起源也是在这台机器,后来安装了 Proxmox VE,将镜像站迁移到了另一台专用机器。
2023年,我了解到系里有一套仿真靶场平台,但软件十分难用,每个赛题环境都是独立的虚拟机,启动缓慢且占用资源巨大。为了给系里学生更好的实战体验,在与老师商讨和评估后,决定建设自己的开源靶场平台。系统为 3节点的深信服超融合 HCI。这些硬件后来由小组代为管理,成为了现今虚拟化资源的来源。
硬件条件
包括三台物理机,每台装有两颗 Xeon E5-2650 v4 和 192GB 的内存。此外还有两台华为 S5720 万兆交换机,一台承担存储网络,一台承担业务和管理网络。存储为戴尔 4T 企业级 SATA 盘 + 英特尔 480GB 企业级 SDD 缓存,总可用存储约 24 TB。


软件环境
原靶场系统自带的虚拟化平台是深信服超融合 HCI,由于版本较老旧(2019年)且已过维保期无法升级,易用性较差,管理面板繁琐且功能局限。尤其是底层的 RHEL 内核版本为 Linux 3.x,存在很大的安全隐患。
不过不得不说深信服的服务还是很不错的,即便是过保的设备,依旧有工程师帮我们解答疑惑,甚至是远程调试困扰了我们很久的 Kernel Panic 问题(这个问题在下面详细展开)。
故障排除
运行过程中发现其中一个节点时常会 Kernel Panic,排查了内核日志、BMC日志均没有明确的报错,此时就考虑肯定是硬件故障,导致日志没有记录/落盘存储。
由于部分设备仍在线上运行,为避免暴露某些网络拓扑,图片中对内网 IP 也打了马赛克。
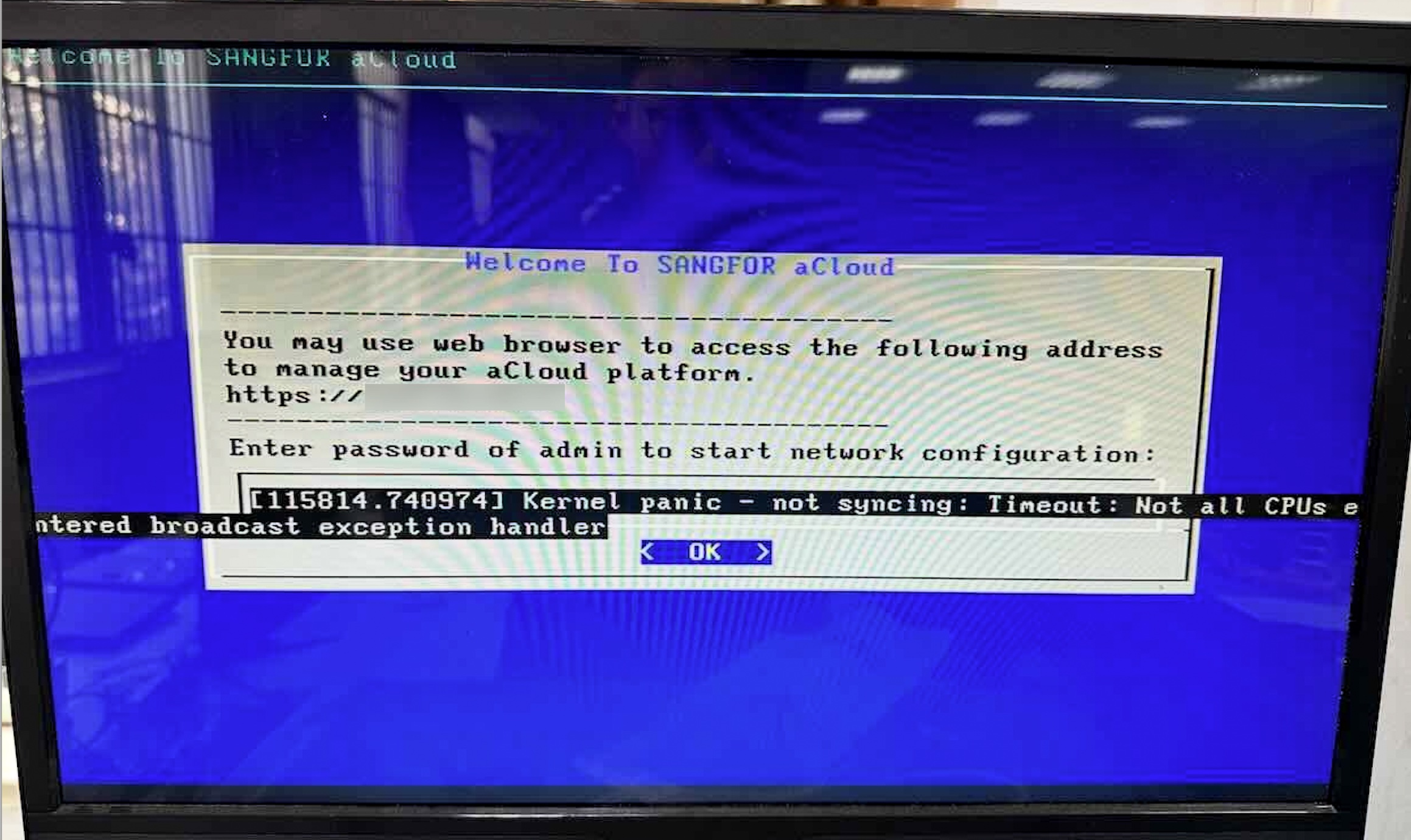
Kernel panic - not syncing: Timeout: Not all CPUs entered broadcast exception handler 这个错误通常是多核 CPU 系统中某些核在处理关键中断(broadcast exception)时未能及时响应 导致内核 panic 的现象。
我们当时考虑的原因,要么是 CPU 本身有故障,要么是主板微码问题。但三台服务器配置和批次都是一模一样的,也相互替换过电源、内存,也调整过主板 ACPI、C-States 等参数,依旧无法解决。
困扰了一个月后,换了一块浪潮的 X99 主板,问题立即消失。因此基本可以判断,是主板上硬件故障导致的。
拥抱开源之路
深信服 HCI 在当今企业级应用中确实是作为 VMware 替代者的存在,在热迁移、存储 IO 优化、内存管理方面有一些自主研发的技术。加之当前 VMware 的采购价格因素,相信它会成为优秀的国产虚拟化支撑者。
但由于前述因素,导致我们急需更换更现代的虚拟化底层。由于旧的虚拟化平台是 Proxmox ,且其对 Ceph、SDN、HA 等分布式集群特性支持良好,就决定选它了。
2024 年 1 月左右,全新的 Proxmox VE 8 部署完毕,可喜可贺。然而 VM 迁移过程中也遇到 Agent、网络、磁盘等各种兼容性问题,也花了学弟很长时间解决。
实验室糟糕的供电及环境
由于实验室只有一路供电,且个人用电器较多,断电问题始终困扰着我们。与学弟的聊天记录:
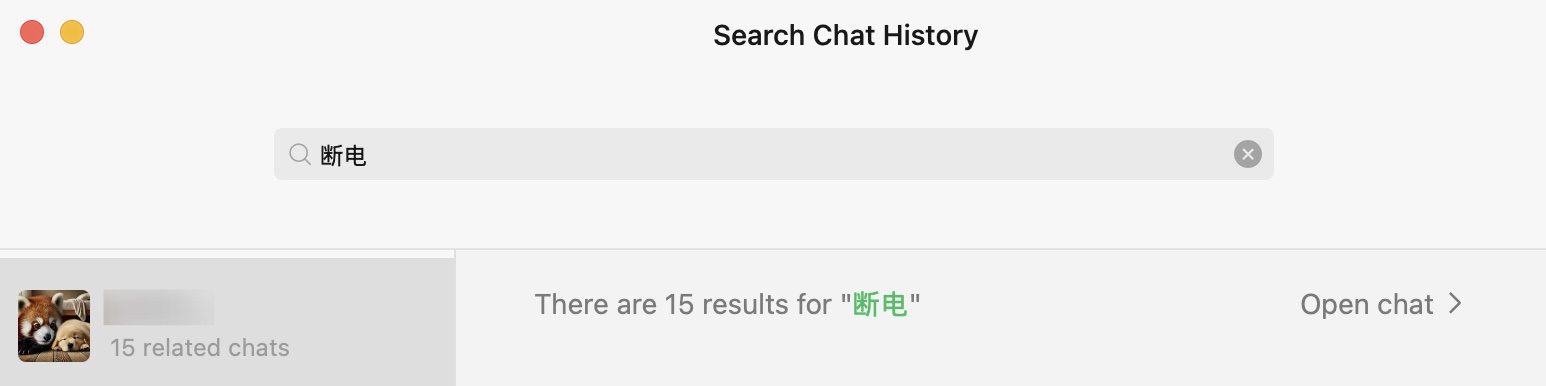
正常来说硬件 RAID 阵列卡都配有一块叫做 BBU(Battery Backup Unit)的小电池,用来给写缓存(通常为内存型如DDR 4)供电。然而我们的超融合架构中存储使用的 Ceph 而不是 RAID,若 vm IO 策略为 Write-Back,则断电时未落盘的数据将丢失,软件层面容易导致 vm 数据丢失或 FS 损坏,硬件层面亦会增加物理 HDD 磁盘的故障率。在一年期间,就发现多个 VM 文件系统遭到损坏,好在使用 fsck 工具都成功修复了。
此外,镜像站也使用裸磁盘映射的方式托管在这上面,频繁的意外断电导致服务可用率低下。
迁移
正式迁移机器时我已经毕业接近一年了,具体实施的事情均由学弟搞定,我只是参与了一些规划以及远程调试了一些配置。
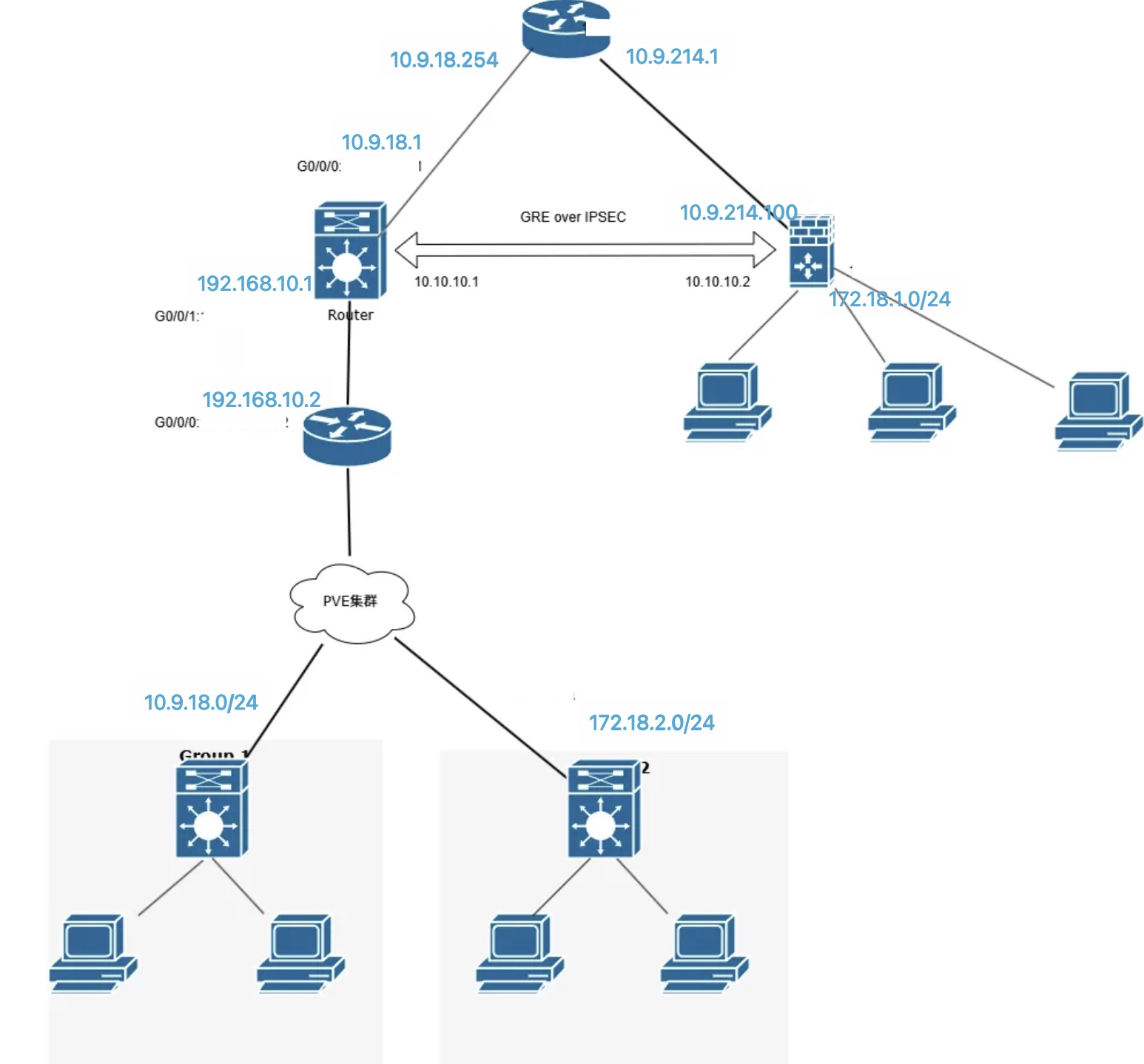
网络背景
- 实验室在校园网的网段:10.9.214.0/24
- 实验室内部网段:172.18.1.0/24
- PVE 网段:
- 业务:172.18.2.0/24
- 管理:172.18.77.0/24
- 存储:<无需变动>
- 数据中心下发的网段:10.9.18.0/24
规划与准备
迁移总体目标是:
- 保障硬件和数据完好无损;
- 尽量让 VM 少改动网络配置:由于之前并没有建设内部 DNS,不同 VM 间服务互联采用纯 IP 地址,而数据中心与实验室不在也无法修改到同一 VLAN,因此难免有些连接至校园网的 VM 需要改动 IP 地址;
- PVE 业务网段要与实验室内部加密互联;
- 完善 Grafana 观测、安全配置等。
硬件
学弟采用了安全可靠的方式搬运服务器,并对线缆打了标签。到现场后发现滑轨螺距不太适配,等待备件到货花费了几天时间,最终安全将硬件安装上架。理线之前 的图片如下。

与实验室网络互联
由于实验室与数据中心提供的网段没有直接路由,而是要跨学校的三层核心交换机,因此直接路由变得不太可行。若要达到实验室与 PVE 三层互通的效果,最直观的想法是两端网络设备建立 VPN 隧道,随后添加路由。
实验室现有一台思科三层交换机和一台支持 IPSEC 的防火墙,此外还闲置一台华为 AR 1220,亦支持 IPSEC。因此打算将 AR 1220 搬到数据中心,当作出口路由器,而集群中原有 S5720 则当作三层交换机。
IPSec 隧道只支持封装、加密单播报文;GRE 可封装、加密单播和组播报文,但不安全。一种经典的方案是结合两者优点,通过IPSec over GRE方式或GRE over IPSec方式实现设备间的互通。
参考:https://support.huawei.com/enterprise/zh/doc/EDOC1000079675/12d76f11
我们选择 GRE over IPSec 的方式,因为 GRE 支持组播和广播,一方面是建立广播链路后,对于 SMB、AirPlay 等依赖广播进行设备发现的协议非常友好;另一方面是日后可扩展 OSPF,例如加一路 Wireguard 来提升两端连接性能。
GRE只负责封装和传输,它本身不提供任何加密或认证机制。
而 IPSec 是一个协议簇,目标是在IP层提供安全服务。其核心协议包括三个:
AH (Authentication Header) - 认证头协议
AH 用于保证数据来源可靠和数据完整性,会在原始IP包头后面插入一个“AH头”,这个头包含了认证信息。它会对整个IP包(包括IP头和数据载荷)进行完整性校验。
ESP (Encapsulating Security Payload) - 封装安全载荷协议
ESP 用于保证数据机密性和防重放,它使用加密算法(如AES、3DES)对数据载荷进行加密。
IKE (Internet Key Exchange) - 互联网密钥交换协议
IKE 用于自动协商密钥和建立安全联盟(SA),在通信双方之间安全、自动地协商出加密参数。
IPSec 有两种应用范式:传输模式和隧道模式。
参考:https://support.huawei.com/enterprise/zh/doc/EDOC1100301617/c5d5a9b
在传输模式下,AH头或ESP头被插入到IP头与传输层协议头之间,保护报文载荷。由于传输模式未添加额外的IP头,所以原始报文中的IP地址在加密后报文的IP头中可见。以TCP报文为例,原始报文经过传输模式封装后,报文格式如所示。
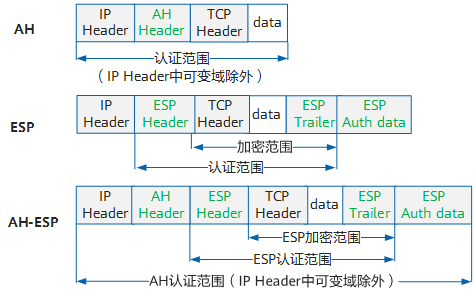
在隧道模式下,AH头或ESP头被插到原始IP头之前,另外生成一个新的报文头放到AH头或ESP头之前,保护IP头和报文载荷。以TCP报文为例,原始报文经隧道模式封装后的报文结构如图所示。
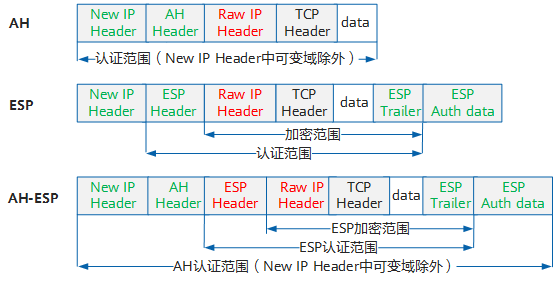
我们采用的当然是隧道模式,配置步骤大致为:
定义组件
定义 ACL ➡️ rule permit gre source 10.9.18.1 destination 10.9.214.100
定义 IPSec Proposal ➡️ 封装模式: tunnel, 加密认证算法
定义 IKE Peer ➡️ 对端公网IP, 预共享密钥
组合应用
创建 PSec Policy ➡️ (关联以上ACL、Proposal、Peer三者)
创建GRE隧道接口 ➡️ (配置源/目地址和隧道私网IP)
绑定 ➡️ 在GRE隧道接口下应用IPSec策略
流量转发
- 配置路由 ➡️ 将内网数据包的目标指向Tunnel隧道口
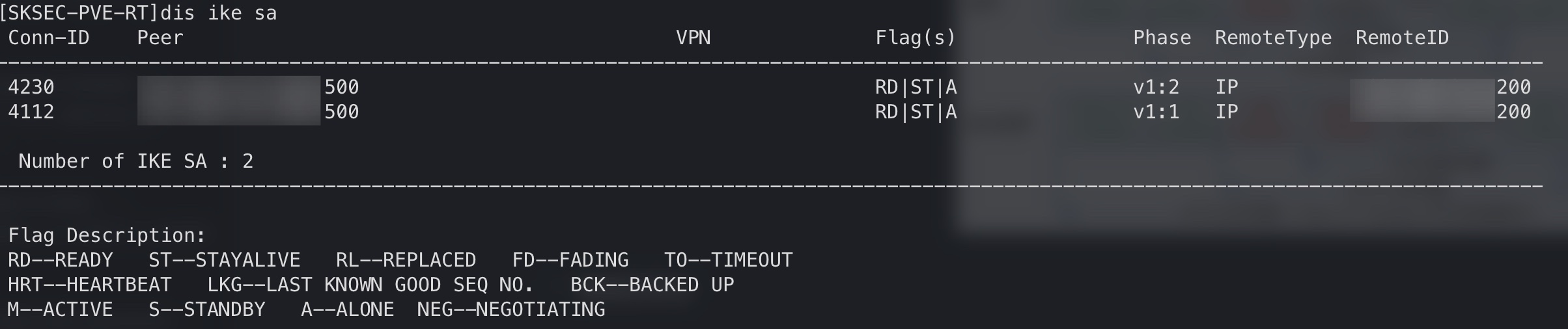
配置完成后,查看 ike sa:
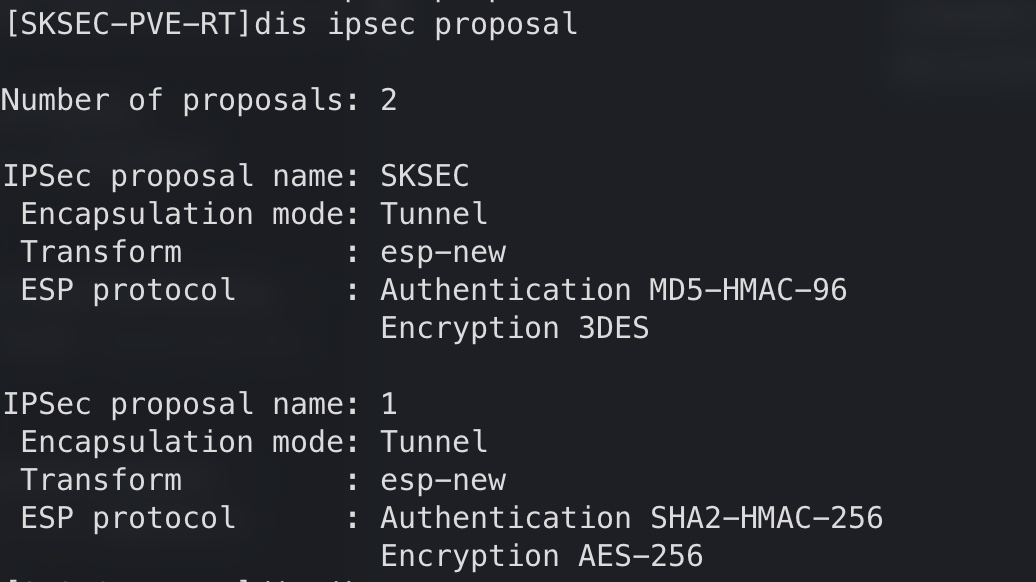
查看 ipsec proposal:
隧道接口成功建立:
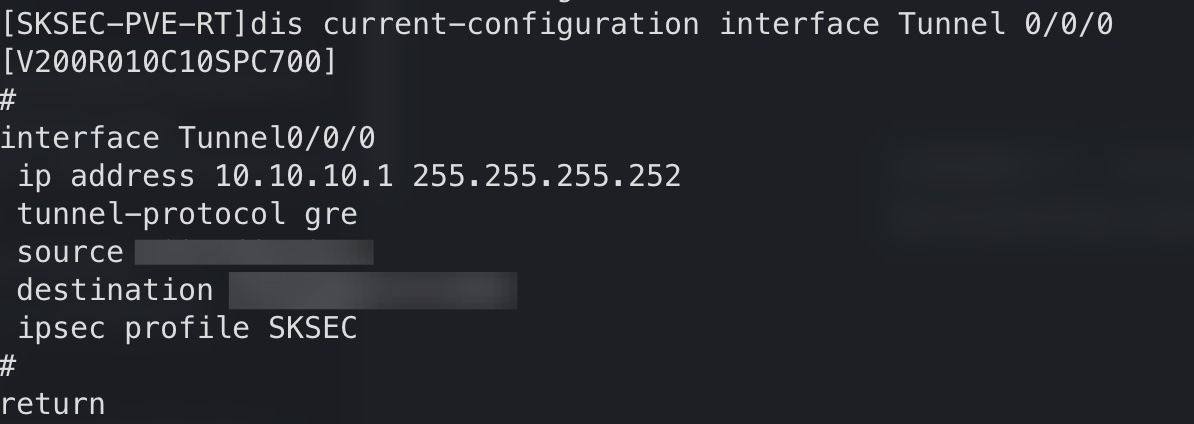
观测及安全
Prometheus 系列的主要就是三大组件:Node Exporter 用来数据采集,Prometheus 定期主动去 Node Exporter 暴露的端口上拉取数据,Grafana 通过 PromQL 查询出数据,然后做可视化。
目前对 Proxmox VE、Ceph、磁盘 SMART 进行了采集。
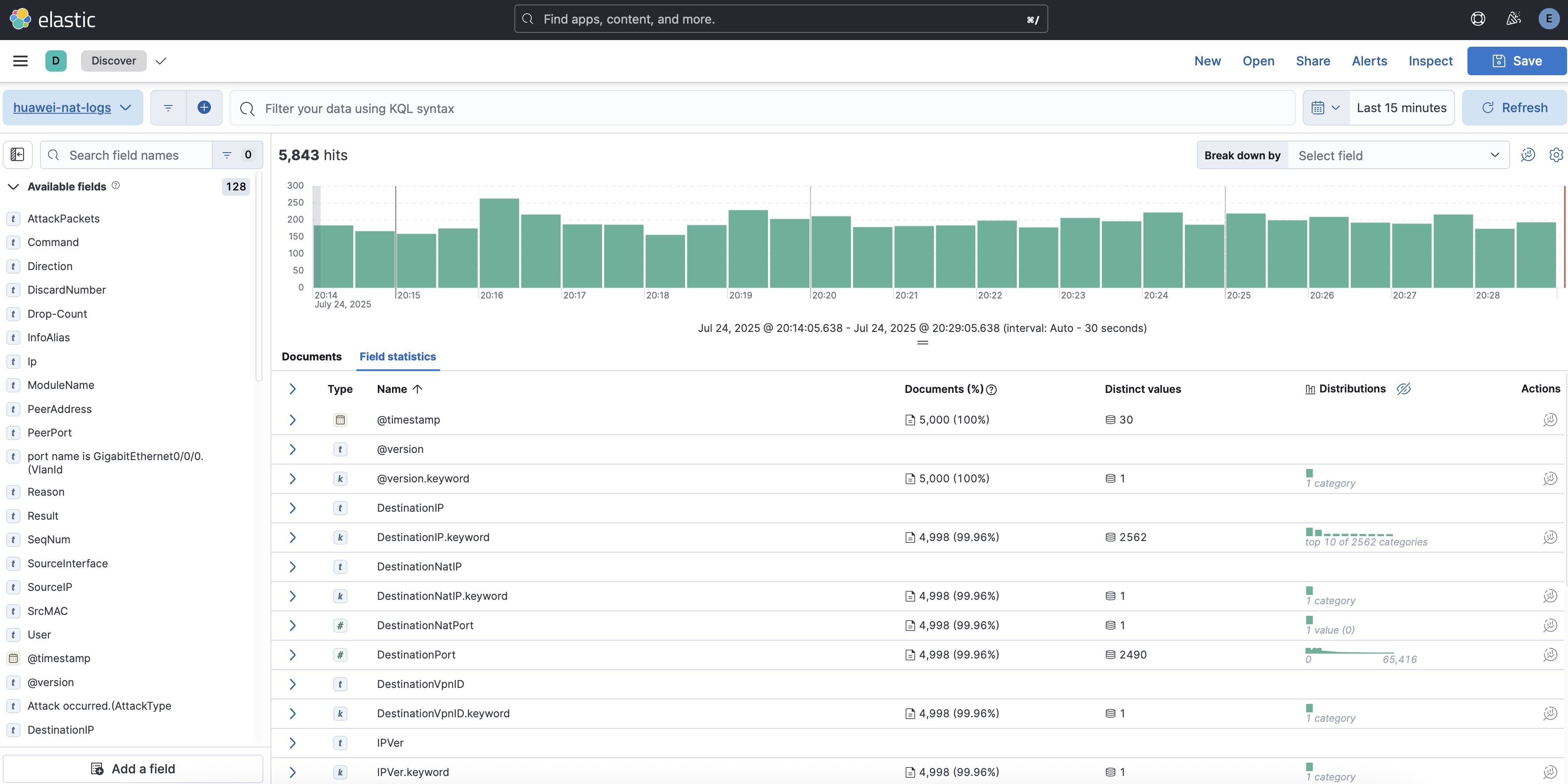
此外,还对路由器 NAT 日志进行了采集,发送至 syslog,再由 logstash 接收,保存至 ElasticSearch。
这里分享一下我们华为 AR 系列路由器适用的 logstash 配置文件:
1 | input { |
后记
由于时间缘故,暂时只能分享这么多了。其实还有很多安全和运维方面的设计和实施心得,虽然自己以后估计也不专职从事这块的工作,但几个人一起折腾网络设备还是挺有意思的。我也非常佩服学弟的研究和专注能力,他自己从一台完全没有手册的杂牌防火墙摸索出了 IPSEC 配置的命令。也很佩服另一位学弟,他 JAVA Web 很强,之前反序列化的那些链子都是他教的我。他俩目前都在考研,希望他俩都能有好的归宿。也非常感激本科实验室在过去的几年里对我的培养,同时感谢网信部门提供的一些实践机会,在那里我们接触到大量的企业级网络和安全设备。
希望我能在新的学习阶段,保持一颗求知和探索的心,多一分专注,少一些摸鱼,尽快让自己的研究工作走向正轨,用成果来回馈曾经支持和关注过我的人。
记一次协助本科实验室迁移物理服务器集群的经历
https://www.catop.top/2025/07/23/a-server-cluster-migration/