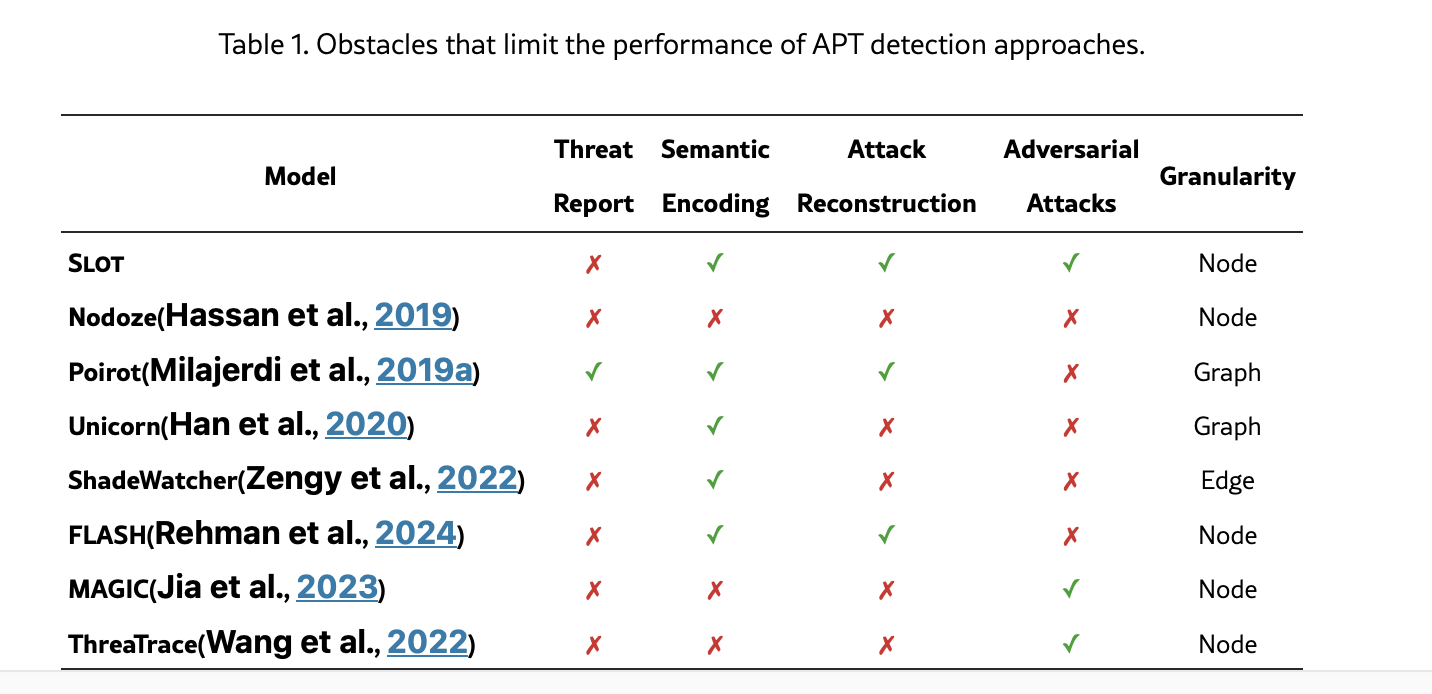
论文阅读 - Slot: 基于图强化学习的溯源图APT检测
主要技术: 注意力机制挖掘潜在行为;图强化学习
发表: arxiv24
图学习类别: 图学习+嵌入向量库
方法分类: 图学习
概要: 使用注意力机制挖掘潜在重点行为,建立边以增强图表示;首次将强化学习引入溯源图分析,采用强化学习进行邻居选择,在抵御对抗方面效果明显。
特色: 注意力机制;强化学习
摘要
使用注意力机制挖掘潜在重点行为,建立边以增强图表示;首次将强化学习引入溯源图分析,采用强化学习进行邻居选择,在抵御对抗方面效果明显。
文章提到的主要贡献为:
- 提出了一种先进的图挖掘技术,能够高效地发现图中多层级的隐藏关系,例如因果关系、上下文关系和间接关系。
- 首次将强化学习引入溯源图分析。通过嵌入语义和拓扑特征,并利用强化学习的自适应动态,Slot能够有效应对高度对抗的环境。
- 实现了自动构建攻击链、攻击路径识别。在真实世界的数据集进行了全面评估,结果证明了Slot在检测APT、抵御对抗攻击以及支持制定有效防御策略方面的能力。
方法
潜在行为挖掘
- 潜在行为挖掘对后续图学习的帮助
- 潜在行为挖掘旨在发现由多个“原子操作”组成的、有意义的“高级行为路径” 。例如,一个
connect->recv->write->exec的序列可能代表了一个完整的“下载并执行”的恶意战术。 - 加速信息传播,解决“远距离依赖”问题:复杂的APT攻击中,攻击链条可能很长。标准的GNN信息传递机制中,一个节点的信息需要经过多层(多个hop)才能传播到远处的节点,这可能导致信息在传播过程中衰减或丢失。
- 通过挖掘和建立一条直接的“潜在”边来连接这两个远距离的节点,信息可以在GNN的一层中直接从攻击起点传播到终点 。
- 潜在行为挖掘旨在发现由多个“原子操作”组成的、有意义的“高级行为路径” 。例如,一个
- 使用注意力机制的动机、实现细节
- 动机:从海量可能的行为路径中,自动地、有重点地筛选出那些最关键、最能代表特定行为模式(无论是恶意的还是良性的)的路径 。
- 潜在行为挖掘之后图谱结构变化的直观理解
- 节点不变,边增加了,图变稠密了
基于强化学习的图嵌入
SLOT 采用的也是「图学习+嵌入向量库」的方法范式,回顾一下目前看过的这种范式的文章还有:Magic。
工作流程为:
- 在语义编码阶段,节点的语义特征和拓扑特征被嵌入到向量中。
- 基于节点特征向量的相似性计算,我们设计了一种自适应的Bandit邻居选择器,使用强化学习。
- 最后,我们通过整合多种关系(包括系统调用和潜在关系)来聚合特征,生成更新后的节点特征向量。
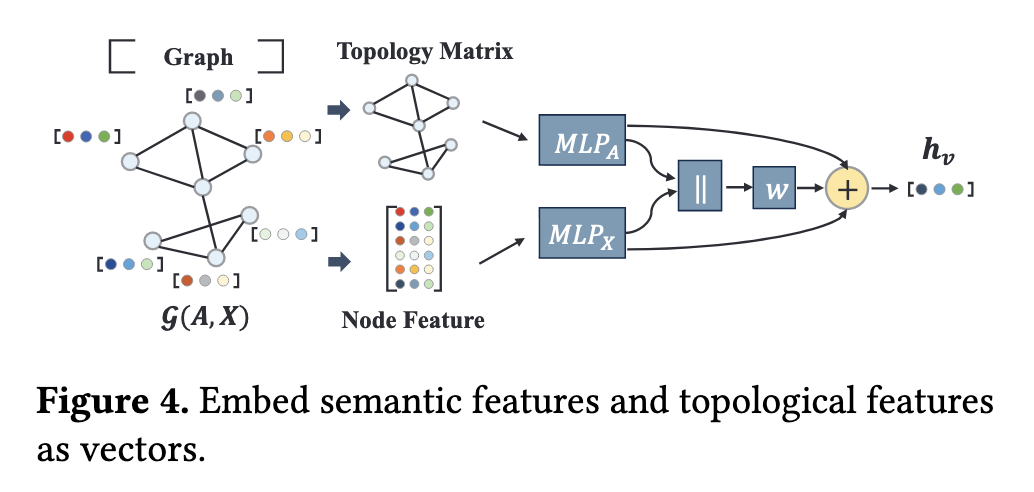
特征语义编码
SLOT 也是结合节点属性和图结构特征来编码节点:
节点属性特征:节点自身的描述信息(下称“字面描述信息”),比如进程的名称、命令行参数、文件路径。SLOT 使用 Word2Vec 生成原始嵌入(64维),并通过一个简单的多层感知机(MLP)来处理这些特征,得到一个基于属性的向量表示 $h_X$。
图拓扑特征:即节点在图中的连接关系和结构位置 。同样使用一个MLP来处理描述全图连接关系的邻接矩阵A,得到一个基于拓扑的向量表示 $h_A$
总结一下的话,对节点属性特征的编码主要就是有两种方式:a) 使用 word2vec、FastText、Bert 等语言模型对字面描述信息进行编码;b)使用节点的类型编码,常见的是 one-hot 编码;c)使用统计信息,例如节点的度、PageRank 值、聚类系数等。
而这篇文章告诉我们的是,可以首先通过Word2Vec等方式获得节点的初始特征,再套一层特征变换(MLP)。结合文中方法而言,将节点属性和拓扑特征这两个差异性大的特征矩阵,都各自经过一层 MLP,模型可以学习到一种较优的属性融合方式。
这种“分别变换,再行融合”,实现了异构特征的自适应融合。是对我做机器学习任务的一个启发。
自适应 Bandit 邻居选择
「Bandit」这词用的挺妙的,意为“土匪”。查这个词的时候还看到一个 Github 上的仓库https://github.com/PyCQA/bandit,Bandit is a tool designed to find common security issues in Python code.
在强化学习中,有一个“多臂老虎机”(Multi-armed Bandit)模型,由于我暂时没涉猎强化学习,建议参考:https://hrl.boyuai.com/chapter/1/多臂老虎机/
简单来说,「多臂老虎机」目标是在操作 T 次拉杆后获得尽可能高的累积奖励。由于奖励的概率分布是未知的,因此我们需要在“探索拉杆的获奖概率”和“根据经验选择获奖最多的拉杆”中进行权衡。“采用怎样的操作策略才能使获得的累积奖励最高”便是多臂老虎机问
题。(图片来源:boyuai.com)

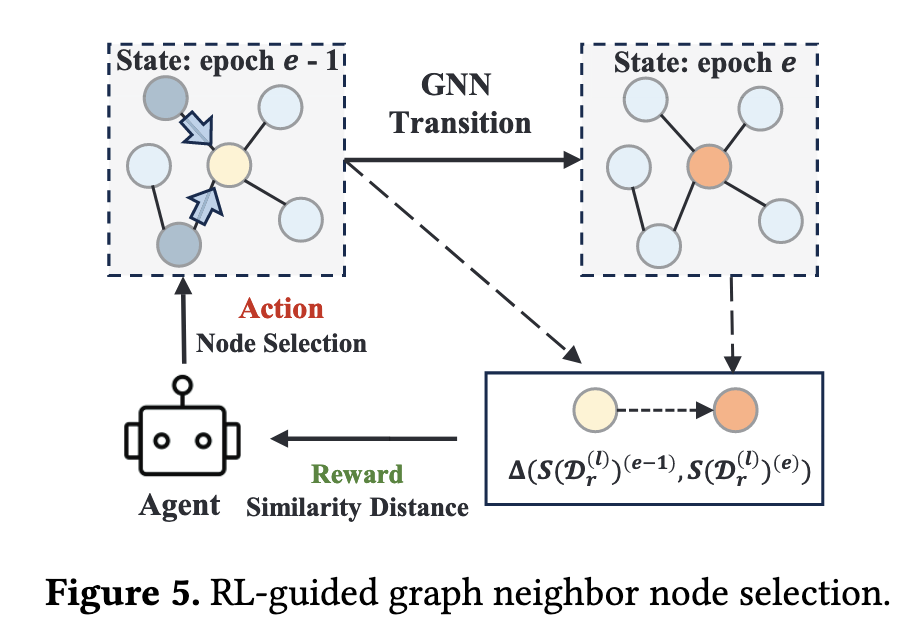
回到本文的任务中,在从中心节点 v 及其邻居收集信息之前,采用 Top-p 采样,根据不同的关系过滤相似的邻居。第 l 层关系 r 的过滤阈值 $p_r^l$ 定义在 [0, 1] 范围内,表示从所有邻居中选择的比例。利用强化学习寻找最优阈值。
使用强化学习的目的是实现最佳的邻居筛选,即为每一种关系类型(Read、Write、Connect等)学习到一个最佳的邻居筛选阈值,以期过滤掉伪装节点。经过筛选后的图再进行后续的邻居消息聚合步骤。
根据强化学习的模型框架,学习过程如下:
- 代理:任务是为每一种关系类型(如“读”、“写”、“连接”等)学习到一个最佳的邻居筛选阈值 pr(l) 。
- 状态:用“所有训练节点与其邻居的平均相似度距离”来定义状态 。距离越小,说明筛选出的邻居质量越高,状态就越好。
- 动作:代理做的动作就是调整筛选阈值。
- 奖励:这是给代理的反馈。如果一个动作(调低阈值)使得筛选后的平均邻居距离变小了(即邻居更相似了),就给代理一个正奖励 (+1)。反之,如果距离变大了,就给一个负奖励 (-1) 。如 Figure5 所示,新旧状态下平均相似度距离的变化量为 $\Delta(S^{e-1},S^{(e)})$。
邻居信息聚合
文中的式10、式11表示了邻居信息聚合的步骤,使用两个步骤的聚合来结合上RL所得的筛选阈值:
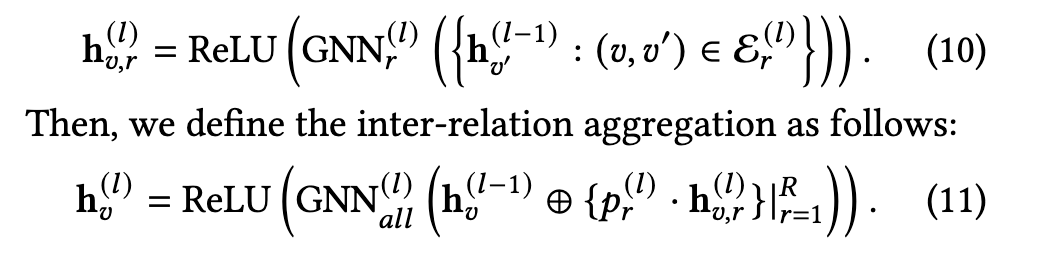
- 对于某节点v的关系r,模型会把所有通过了筛选的邻居节点的信息聚合到中心节点上,生成一个特定于该关系的中间向量 $h^{(l)}_{v,r}$
- 把节点v的所有不同关系向量聚合起来,使用第二步中强化学习学到的**最优筛选阈值 $p_r^{(l)}$**,得到当前节点最终向量 $h_v^{(l)}$
威胁检测过程
使用「学习检测」和「异常检测」并行进行检测,分别使用 MLP 和孤立森林。
基于 MLP 的学习检测
为了与图神经网络联合训练相似性度量,一种启发式方法是在GCN聚合层之前将其作为新层附加。
这边损失函数比较复杂, 我也没有搞特别明白,暂且请教了下 Gemini。它的训练过程优化了一个组合损失函数:
$$
\mathcal L= \mathcal L_{GNN}+\lambda_1 \mathcal L_{Simi}^{(1)} + \lambda_2 ||\Theta||_2
$$- $\mathcal L_{GNN}$:主要的GNN损失。它衡量的是最终的节点嵌入向量 $Z_v$ 在经过MLP分类后,其预测结果与真实标签(良性/恶意)的差距有多大 。这是最核心的监督信号。
- $\mathcal L_{Simi}^{(1)}$:一个辅助的相似度损失。它要求模型在第一层计算出的、用于感知相似度的特征向量,也应该能初步地区分良性与恶意 。这样做可以倒逼模型从一开始就学习更有区分度的特征表示。
- $||\Theta||_2$:一个L2正则化项,用来防止模型过拟合,增强其泛化能力 。
基于孤立森林的异常检测
孤立森林 (Isolation Forest, iForest) 是一种无监督算法,擅长快速从数据中找到“离群点“。
iForest 通过随机构建一系列决策树来尝试“孤立”每一个数据点,那些异常的点因为“与众不同”,通常只需要很少几次分割就能被完全孤立出来,因此它们在树中的平均路径长度就很短 。
根据这个平均路径长度,算法会为每个节点计算一个 [0,1] 之间的异常分数 (Anomaly Score) 。
最终决策
在并行检测之后,Slot 将两个分类器的结果结合起来做出最终决策。如果监督学习模型对某行为(无论是良性还是恶意)做出了高置信度的预测,则采用该预测。另一方面,如果异常检测模型表明该行为可能存在异常,则将其标记为异常。
效果评估
数据集
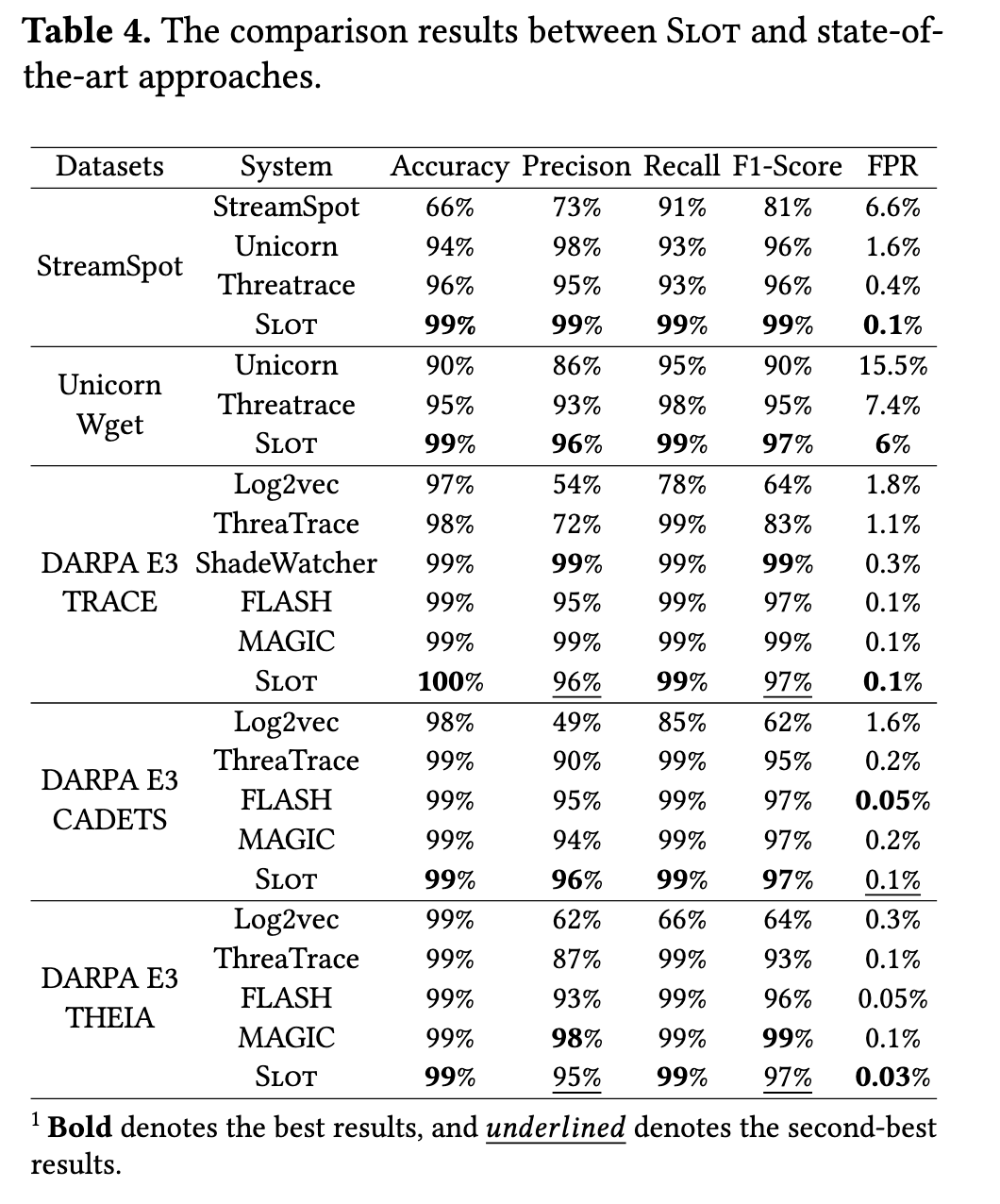
选用图级别的 StreamSpot 和 Unicorn,以及节点级别的 DARPA E3(Trace、Cadets、Theia)。节点级别对比的工作有 Threatrace、Log2vec、FLASH、MAGIC,边级别对比的工作为 ShadeWatcher。
结果分析
- RQ1:与当前最先进的方法相比,Slot在检测APT方面有多有效?
- RQ2:使用Slot会产生多少系统开销?
- RQ3:Slot的各个组件在实现其预期功能方面有多有效?
- RQ4:不同的超参数如何影响Slot的检测能力?
- RQ5:Slot对对抗性攻击的鲁棒性如何?
- RQ6:Slot在辅助人工验证警报方面有多有效?
RQ1: 有效性分析
RQ2: 开销分析
与基于掩码图学习的 Magic (https://www.catop.top/2025/06/08/MAGIC-reading-report/)做了对比,也提到 Magic 的开销瓶颈其实在于 KNN 距离的计算。
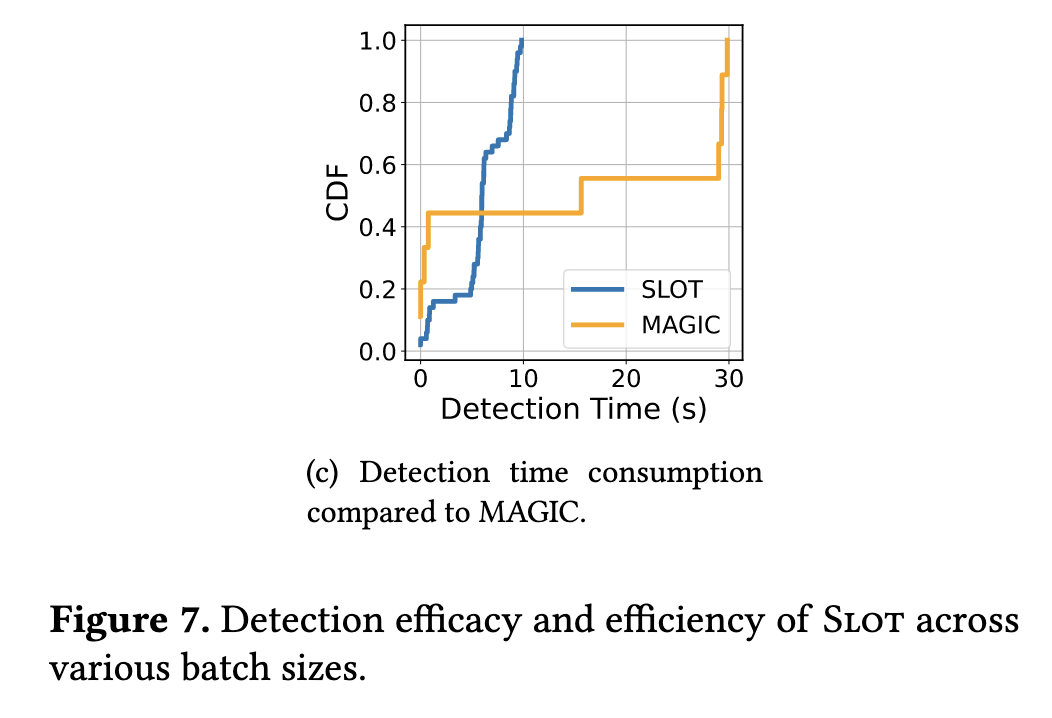
这张图里面纵轴的 CDF 指的是累积分布函数(Cumulative Distribution Function),横轴表示完成一次检测所需的耗时,纵轴代表横轴对应的时间点之前,已经完成的检测任务所占的累积比例。
RQ3: 组件消融实验
我比较关心基于强化学习的邻居选择的作用,根据中间的图来看带有 awareness 的效果显著要高。
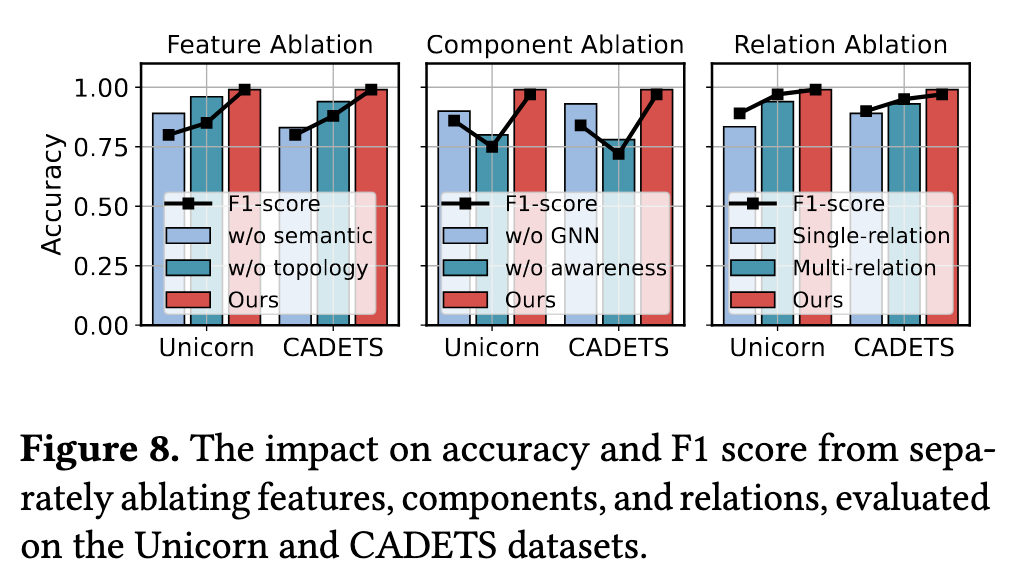
我还比较关注基于注意力的潜在行为挖掘的作用,根据右图来看引入隐关系信息对效果也有一些提升。
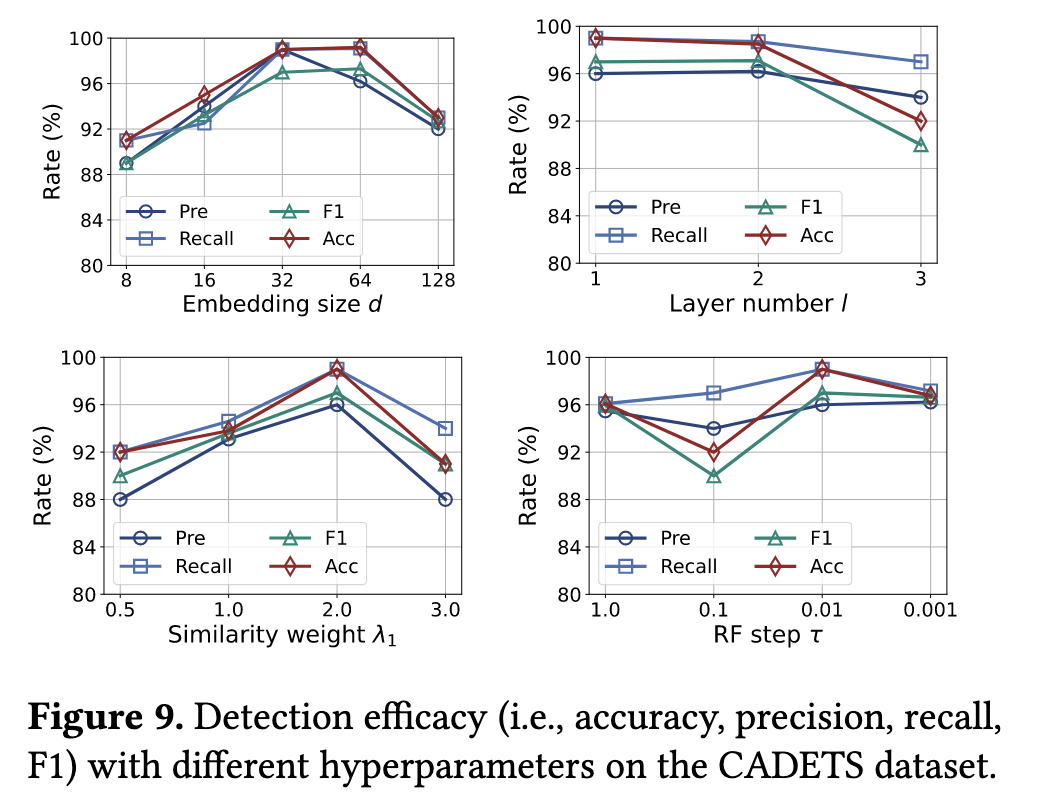
RQ4: 超参数选择
模型总体比较复杂,可调节的超参数多,这边对一些超参数进行了测试。
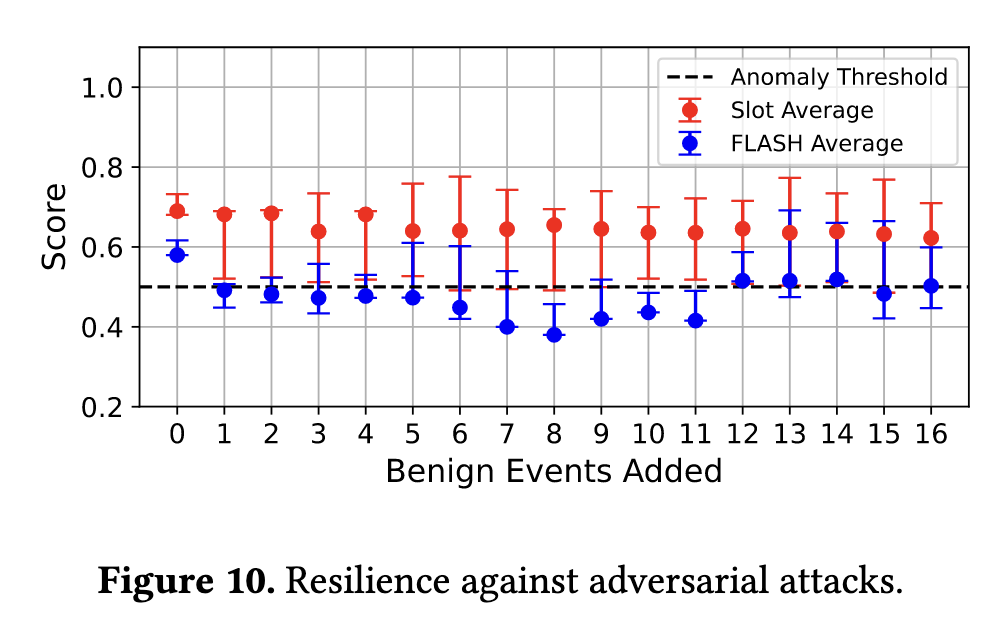
RQ5: 对抗攻击的鲁棒性
文章采用了两篇文献所提到的攻击方法,主要涉及在攻击图中插入良性结构:
- Akul Goyal, Xueyuan Han, Gang Wang, and Adam Bates. 2023. Sometimes, you aren’t what you do: Mimicry attacks against provenance graph host intrusion detection systems. In 30th Network and Distributed System Security Symposium.
- Mati Ur Rehman, Hadi Ahmadi, and Wajih Ul Hassan. 2024. FLASH: A Comprehensive Approach to Intrusion Detection via Provenance Graph Representation Learning. In 2024 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 139–139.
对抗攻击方面与 Flash 这一个工作进行了对比:
总结与思考
这篇文章尽管还是 Arxiv 2410(博客写作时间为25年6月底),但感觉值得我学习的点有许多,包括但不限于:
- 基于注意力的图增强方式:GNN 是逐跳进行邻居信息传播的,在此过程中远距离邻居间的关系被“淡化”。借助注意力机制来自动化筛选出需要重点关注的路径,并添加虚拟的边,那么就有助于节点的表示。借助这个思路,感觉或许也可以用一些攻击语义进行图增强,例如 ATT&CK 等。
- 特征语义编码:对字面特征通过 Word2vec 提取嵌入,对拓扑特征使用邻接矩阵进行表示,最后两者分别过一层 MLP 进行聚合,看起来是一种融合不同尺度/语义特征的有效方法。
- 将强化学习引入溯源图:据称为首个这样的工作。强化学习在图中主要起到邻居选择的作用,像是给邻居节点加入了一层“门控”,若开/关门后邻居节点更“相似”了则给予奖励。但由于个人对强化学习不甚了解,不太能理解这样设计奖励的动机是什么,有更深入理解的伙伴可以交流。
- 并行使用使用 MLP 和孤立森林进行学习检测、异常检测。感觉从以往读过的文章来看,这类工作并不是很多,这篇文章告诉我们这是可行的。
论文阅读 - Slot: 基于图强化学习的溯源图APT检测