论文阅读 - MAGIC: 通过掩码图表示学习进行APT检测
这篇文章光着急复现了,文章并未通读,以下主要是结合代码来对方法细节进行自己的记录,整理的挺乱的,但迫于这周给自己定的计划有更新这篇阅读博客,就先更了,回头再改改。
MAGIC 是「图学习+嵌入向量范式」的节点级别溯源图 HIDS,设计图注意力网络(GAT)和掩码图学习,通过对节点类别和边存在性的重构,来引导模型从良性数据上学习一个编码器。随后采样良性节点进行编码,并计算 KNN 平均距离作为良性基线。检测阶段对亦节点进行编码嵌入,KNN 寻找良性节点邻居并计算平均距离,与良性基线共同计算得到异常分数。文章发表在 USENIX 24’,作者来自复旦大学、中山大学等。
💡图学习+嵌入向量范式:感觉溯源图 HIDS 的论文方法大体可以分为三种范式:图学习+分类模型、图学习+重建损失异常、图学习+嵌入向量库。具体例子可见我的另一博客,传送:图学习任务类型
摘要
以往的溯源图 APT 攻击检测存在一些典型不足:1)需要包含攻击数据和 APT 的先验知识;2)无法提取蕴含在溯源图中的丰富上下文信息;3)计算成本和内存开销大。
本文提供了一种灵活的自监督溯源图 APT 检测方法,能够在实体级别和批量日志级别两个粒度上实现检测。MAGIC 利用掩码图学习对良性系统实体和行为进行建模,实现图谱的深度特征提取和结构抽象。在检测过程,利用离群值挖掘系统异常行为。此外,MAGIC 专门设计了模型自适应机制以处理概念漂移问题。对 StreamSpot、Unicorn Wget、DARPA E3 三个数据集上进行了评估,表明其在所有场景中都取得有前景的结果,并在性能开销方面比 SOTA 方法有巨大优势。
感觉这篇文章背景设定广泛,是一篇通用性质强的文章。读完并且复现完了觉得确实不错,为溯源图的学习和表征提供了一种通用的编码方式。
读前思考
MAGIC 是如何处理概念漂移问题的?
与基于重建误差的方法相比,这种自编码器的方式在训练的监督信号上有何特点?
是否能通过这种编码器的方式,实现全图嵌入?
方法
MAGIC的核心在于利用掩码图表示学习来建模良性系统实体和行为,从而在溯源图上高效地提取深层特征和抽象结构。
MAGIC 设计的编码器是对节点进行嵌入表征的,那对于整图来说就可以采用池化或加权平均等方式获得整图嵌入。因此文章对批次(图)级别(StreamSpot、Unicorn Wget)和节点级数据集(DARPA E3)均有所体现。
图构建和特征工程
节点特征选择
趁这个机会正好熟悉一下常见几种数据集的特征。
有类型日志:one-hot编码类型
“对于提供了明确类型的日志,MAGIC 将节点和边的类型进行编号,作为标签。”
DARPA E3
采用的节点类型有:
1
['SUBJECT_PROCESS', 'FILE_OBJECT_FILE', 'FILE_OBJECT_UNIX_SOCKET', 'UnnamedPipeObject', 'NetFlowObject', 'FILE_OBJECT_DIR']
Wget
采用的节点类型有:
1
['file', 'process_memory', 'task', 'mmaped_file', 'path', 'socket', 'address', 'link']
StreamSpot
采用的节点类型有:
1
['process', 'thread', 'file', 'MAP_ANONYMOUS', 'NA', 'stdin', 'stdout', 'stderr']
无类型日志:哈希处理
“若日志未提供类别标签,则使用
xxhsah对源节点 UUID 和目标节点 UUID 进行编码。”然而根据代码来看,对 StreamSpot、Unicorn Wget、DARPA E3 都采用了节点类型编码,xxhash 只是对 wget 数据集的 src uuid 和 dst uuid 进行了编码,实际构建 DGL 图时并未采用。
数据清洗
主要是对边进行去重。去重后边的初始嵌入为原始几条边的均值。这一步骤在DARPA E3 Trace数据集上平均减少了79.60%的边。
对于这种 one-hot likely 的编码方式,用向量均值表示合理性如何?
特征掩码 (Feature Masking)
在训练前,随机选择一定比例的节点进行掩码(默认为0.5),用特殊的掩码标记替换其初始嵌入,以便后续重构。边不进行掩码。
图编码模块 (Graph Encoder)
包含多层堆叠的图注意力网络(GAT)。GAT层通过聚合节点自身及其邻居的特征(初始嵌入)来生成输出节点嵌入,并使用注意力机制衡量邻居的重要性。最终的节点嵌入由原始节点嵌入和所有GAT层的输出拼接而成。
🤔 对于一个中心节点,其3跳邻居的信息 只包含这个邻居本身,还是也包括这个邻居的邻居?
答:不包括该3跳邻居节点的邻居。一个3层GNN的“感受野”是3跳。它无法直接捕获到4跳邻居的信息。
图解码模块 (Graph Decoder)
图解码器的主要目的是为图表示模块的训练提供监督信号,通过结合掩码特征重构和基于样本的结构重构来优化模型。这与典型的图自编码器(通常同时进行特征和完整结构重构)以及图掩码自编码器(通常放弃结构重构以减少计算开销)有所不同。
掩码特征重构 解码器使用一个类似GAT的层来重构被掩码节点的初始嵌入,并计算特征重构损失(scaled cosine loss)。
基于样本的结构重构 通过对比采样节点对并预测它们之间的边概率来重构图结构。 使用一个简单的两层MLP来预测边概率,并采用二元交叉熵损失。
最终的优化目标函数是特征重构损失和结构重构损失的和。
检测模块
简单来说,区分是否恶意的原则为:“正常”样本在嵌入空间中是聚集的,而“异常”样本则会远离这些正常的聚集区。
模型的训练过程都只使用了良性的数据,意味着模型学习到的embed()函数,其目标就是将正常的系统实体(节点)映射到嵌入空间中的一个相对紧凑的区域。
因此,检测模块的任务就变成了:
- 用所有训练集(纯良性) 的嵌入点,构建一个“正常行为”基线。
- 对于一个测试集中的新样本节点,计算它到这个“正常”参照系中最近的k个点的平均距离。
- 如果这个平均距离非常大,就说明这个测试样本“离群”,即认为是异常节点。这个“平均距离”就成了我们的异常分数(Anomaly Score)。
代码实现
图处理
trace_parser.py
将最原始、非结构化的JSON日志,通过一系列正则匹配和逻辑处理,转换成结构化的边列表(.txt),再从中构建出NetworkX图,并将节点/边类型映射为整数ID。最终产物是包含多个NetworkX图(以node-link格式)的 train.pkl 和 test.pkl,以及各种类型映射和恶意实体信息。
原数据集的节点UUID转换成自己的整数ID,目的:
- 整数ID通常比长字符串UUID占用更少的内存
- 像DGL (Deep Graph Library,MAGIC项目中使用的库) 或 PyTorch Geometric这样的图神经网络库,通常期望或在内部将节点表示为从0开始的连续整数ID。
- 训练图:每个图都有自己的一套从0开始的局部节点ID。这些图被分别保存到 train.pkl 里。(没啥用处,反正训练集都是去掉恶意节点的
- 测试图:会创建一个合并的 test_node_map (UUID -> “全局测试集”整数ID)。这个映射横跨 所有 测试文件。(评估的时候有用,保存在metadata.json中。malicious.pkl也是指测试集中的)
文件作用:
names.json(id_nodename_map) UUID -> 可读名称,如路径或IP对FILE、SUBJECT_PROCESS、NetFlowObject类型的节点获取文件路径、进程名、IP
但最终数据是不包含文件路径、进程名或IP地址的,只包含了节点的类型ID。
训练时使用的节点特征是基于节点类型ID进行one-hot编码得到的( utils/loaddata.py 中的 transform_graph)
types.json(id_nodetype_map) UUID -> 类型字符串read_graphs(): 读取预处理后的图数据,并将其保存为模型可加载的 .pkl 文件- train.pkl: 包含一个列表,列表中的每个元素是一个训练NetworkX图的node-link data表示。
- test.pkl: 包含一个列表,列表中的每个元素是一个测试NetworkX图的node-link data表示。
- malicious.pkl: 包含一个元组,包含恶意节点的整数ID列表和它们的名称列表。
- (新增)node_type_mapping.json 和 edge_type_mapping.json: 保存全局的类型字符串到整数ID的映射。
loaddata.py
输入阶段一生成的
train.pkl, test.pkl, malicious.pkl以及元数据文件,加载数据并转换为DGL图,进行特征工程(节点/边类型ID进行one-hot编码)。输出单个DGL图(train_x.pkl)。
训练
评估
以下仅体现节点级别检测,流程对应model/eval.py中的 evaluate_entity_level_using_knn()。
数据准备 (Data Preparation):
x_train: 来自所有训练图的所有节点的嵌入向量。由于训练图都是良性的,所以x_train代表了海量的、各种类型的“正常节点”的嵌入表示。x_test/y_test: 来自所有测试图的所有节点的嵌入向量和它们对应的真实标签(0或1)。
构建良性参考基线:
- 基于所有正常节点的嵌入构建的K-D树(或等效结构),形成了一个“正常系统实体”的参照空间。
论文中强调的 K-D 树不在代码显式出现,而是
sklearn.neighbors.NearestNeighbors在调用.fit()时,为了优化后续.kneighbors()的查询速度而内部构建的高效索引结构。计算异常分数 (Calculating Anomaly Score):
- 缓存机制: 代码会检查
eval_result/distance_save_{}.pkl是否存在。因为计算所有测试节点到所有训练节点的距离非常耗时,所以第一次计算后会把结果缓存下来,方便后续快速重复实验。 distances_train_sample, _ = nbrs.kneighbors(x_train[idx][:50000], ...): 从海量的正常训练节点中随机采样一小部分(最多5万个),计算它们内部的k近邻平均距离mean_distance,作为“正常节点”的距离基准。distances_test, _ = nbrs.kneighbors(x_test, ...): 为测试集中每一个节点,在x_train(正常节点参照系)中找到其k个最近的邻居。current_distances = distances_test.mean(axis=1): 计算每个测试节点的k近邻平均距离。score = current_distances / (mean_distance + 1e-9): 同样进行归一化,得到每个测试节点的异常分数。
- 缓存机制: 代码会检查
评估 (Evaluation):
auc = roc_auc_score(y_test, score): 使用每个节点的异常分数和真实标签计算总体性能。
有个神奇的地方,代码的
model/eval.py中针对不同数据集硬编码了距离阈值,从而确保复现论文中的结果。实际上改为通过 max f1 的方法来选定 threshold 效果实测也差不多。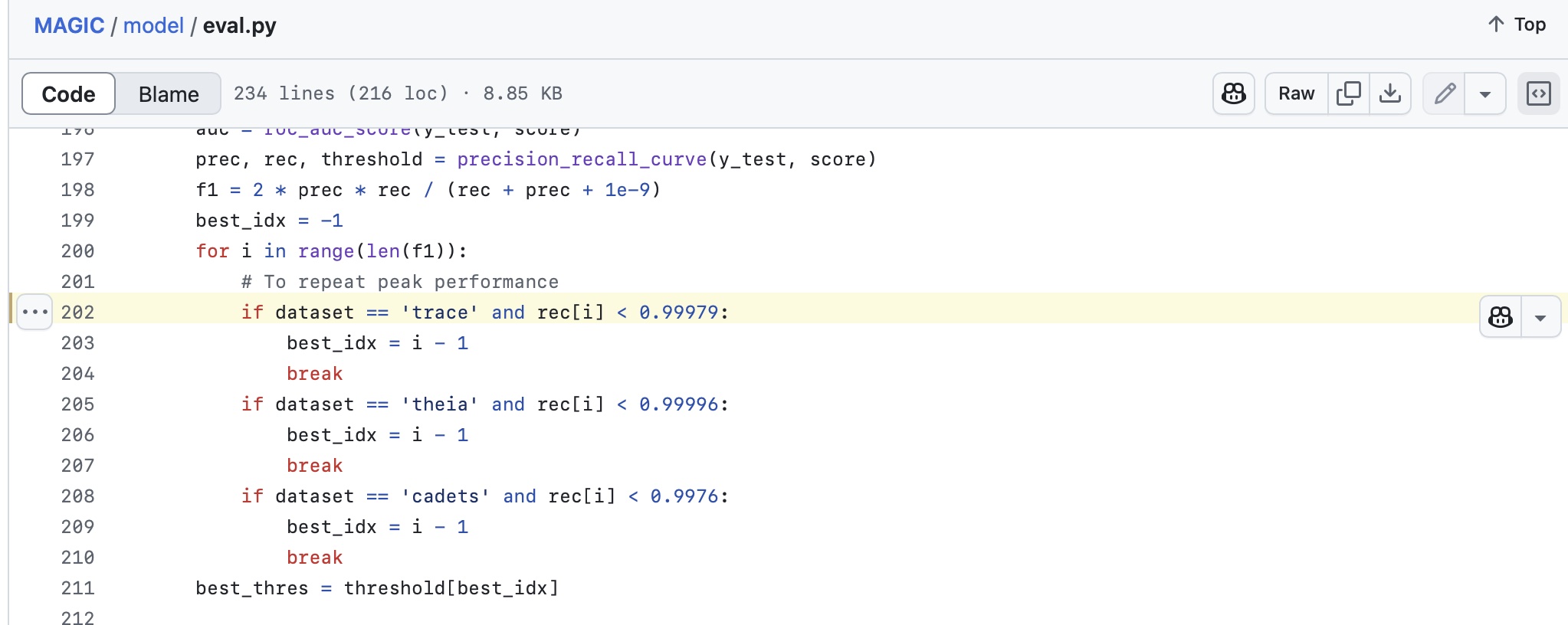
此外还学到了一个 sklearn 一个挺有用的用法
precision_recall_curve(),用于自动评估二分类模型性能:它接收真实的标签列表 (y_test) 和模型预测的“置信度分数”或“概率分数”列表 (score) 作为输入。这个 score 越高,代表模型认为样本属于正类(在这里是恶意节点)的可能性越大。
precision_recall_curve会将所有出现过的 score 值(或者说,是一些关键的 score 值)作为潜在的阈值。对于每一个这样的潜在阈值,它都会计算出一对 (精确率, 召回率)。因此,它返回的 threshold 列表,就包含了所有这些被考虑过的决策阈值点。返回的 prec 和 rec 数组则是在这些相应阈值点(或阈值区间)上的精确率和召回率。
总结与思考
待更新…
知识补充
DGL
DGL(深度图库)使用稀疏矩阵表示,大大减少了计算和内存需求。对于稀疏图,计算复杂度与边的数量相关,而不是节点数量的平方。
邻接表与邻接矩阵
邻接表 是一种链表的集合。对于每个顶点,邻接表中都有一个链表,链表中存储着与该顶点直接相连的其他顶点。
示例: 考虑下面这个无向图:
1 | A |
使用邻接表来表示该图的结构如下:
1 | A -> B -> C |
邻接矩阵 是一个二维矩阵。矩阵的行和列分别代表图中的顶点,矩阵中的元素表示对应顶点之间是否存在边。
示例: 继续使用上述无向图的示例,使用邻接矩阵来表示该图的结构如下:
1 | A B C D E F |
邻接矩阵的优点是在查找特定边的操作上非常高效,时间复杂度为O(1)。同时,邻接矩阵还可以方便地进行图的遍历和某些图算法的实现。然而,邻接矩阵需要较大的存储空间,在稀疏图的情况下,可能会浪费大量的存储空间。
稠密表示与稀疏表示
只存储矩阵中的非零元素(即实际存在的边)及其位置(行和列索引)。
常见格式:
COO (Coordinate List): 存储一个元组列表
(row_index, col_index, value)。CSR (Compressed Sparse Row): 使用三个一维数组:一个存储非零元素的值,一个存储非零元素的列索引,一个存储每行非零元素的起始位置。
CSC (Compressed Sparse Column): 类似于CSR,但按列压缩。
AUC 评估指标
AUC(Area under curve,曲线下面积) 是 ROC 曲线(Receiver Operating Characteristic Curve)下的面积。
- ROC 曲线:横轴是 FPR(假正率),纵轴是 TPR(真正率),通过不同阈值下模型输出的预测概率计算出来的。
- AUC 值的范围:[0, 1]
- 1.0:完美分类器
- 0.5:和随机猜测一样(无区分能力)
- <0.5:模型在反着预测(可以通过翻转标签改进)
论文阅读 - MAGIC: 通过掩码图表示学习进行APT检测