Kairos简单阅读和复现
《KAIROS: Practical Intrusion Detection and Investigation using Whole-system Provenance》是图级别溯源图IDS的方法,发表在S&P24,本文是对其简单阅读和复现的记录。复现过程中遇到了几处环境问题,做了对应解决。
关键方法
时间窗口队列异常分数计算
KAIROS会根据每个时间窗口的可疑节点来增量构建时间窗口队列。
- 如果一个新的时间窗口与现有队列中的某个时间窗口存在共同的可疑节点,那么这个新的时间窗口就会被添加到该队列中;
- 若不存在共同的可疑节点,则会创建一个仅包含该新时间窗口的新队列。
当一个新的时间窗口被添加到队列中时,KAIROS会基于重建误差更新该队列的异常分数,若异常分数超过阈值,KAIROS就会认为该队列异常并触发警报。
TGN
文中KAIROS的TGN Encoder是对边进行嵌入,MLP Decoder 获得该边的预期类别(9种)。
训练阶段:可训练的是TGN、MLP两个模型的参数,目标是最小化实际边类型和从边嵌入预测的边类型之间的差异(交叉熵损失),即重建误差(Reconstruction Error,RE)。
检测阶段:根据边的重建误差,更新队列异常分数。
超参数
邻域采样大小|N|:取经验值20。
例如在E3 - THEIA数据集中,约97%的节点邻域大小为20或更小。
追踪 State Update 的时间窗口:未讨论,但提到默认时间窗口|tw| 为15分钟。
检测策略
如果一个节点满足以下两个属性,则该节点在时间窗口T内是可疑的:
- 异常性:如果一个节点是一条边的源节点或目标节点,且该边的重构误差大于重构阈值,那么这个节点就是异常的。
- 稀有性:如果一个节点对应的系统实体在良性执行中不经常出现,则该节点是稀有的。使用逆文档频率(IDF)来计算节点的稀有性。
复现过程
提供了预训练权重:https://drive.google.com/drive/u/0/folders/1YAKoO3G32xlYrCs4BuATt1h_hBvvEB6C
环境搭建问题
scikit-learn和numpy版本兼容性问题
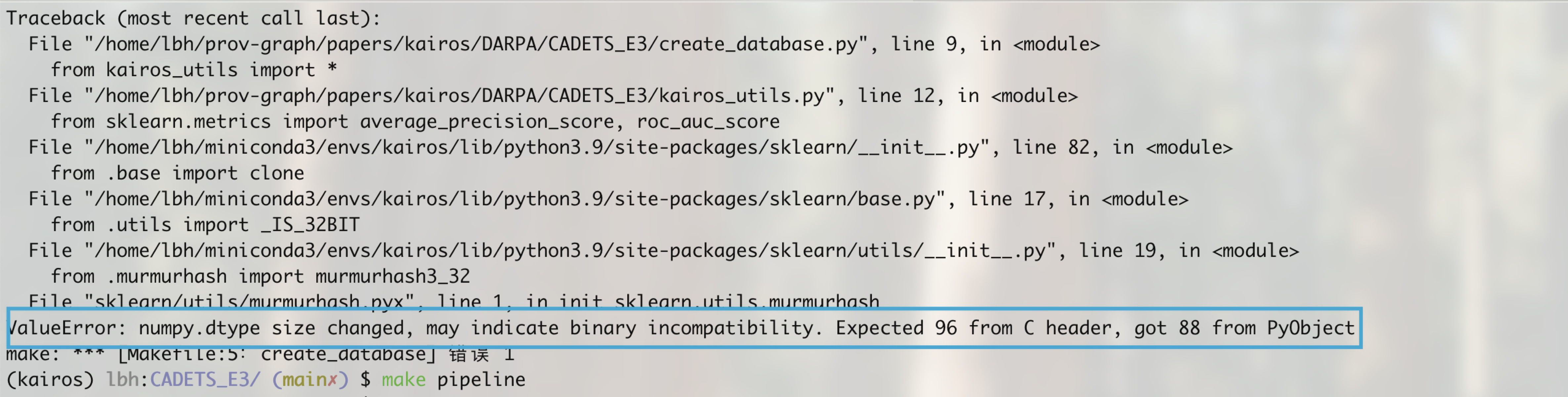
作者给的readme也提到了这个问题(应该)

根据发行时间推算scikit-learn==1.2.0对应的numpy版本:

最终解决:
1
2pip uninstall scikit-learn numpy
pip install scikit-learn==1.2.0 numpy==1.23.5torch_geometric 报错Not compiled with CUDA support
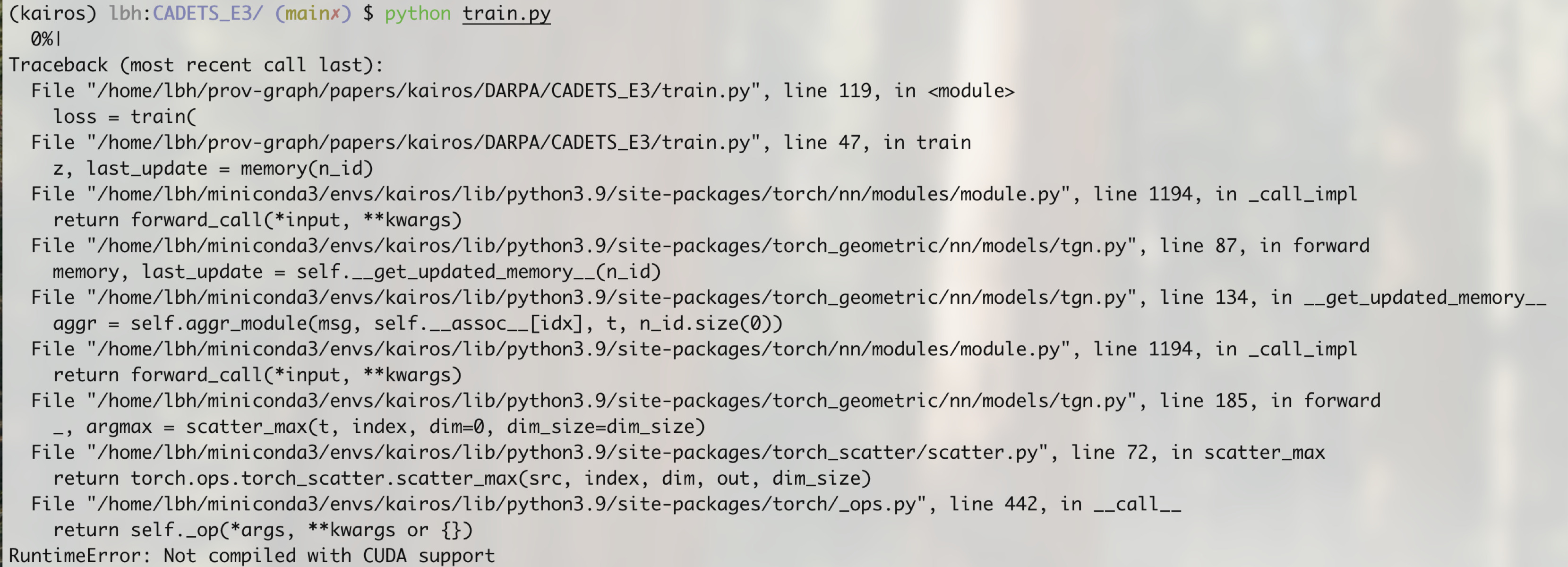
实际上是torch_scatter报错了,首先卸载:
pip uninstall torch_scatter去官方下对应torch和cuda版本的:
安装:
pip install ./torch_scatter-2.1.1+pt113cu117-cp39-cp39-linux_x86_64.whl
测试:
1
2
3
4
5
6
7import torch
import torch_scatter
x = torch.rand(5, device='cuda')
index = torch.tensor([0, 1, 2, 0, 1], device='cuda')
output, argmax = torch_scatter.scatter_max(x, index)
print(output)attack_investigation报错缺库:

pip install python-louvain
知识补充
图学习任务类型
在溯源图IDS中,感觉可以将基于图学习的方法分为三种,取代表性的文章简单归类了下,后面有时间再更新。
图学习+分类模型
首先经过图学习模型(例如GCN),然后输入到标准的分类器中(例如MLP等),输出标签为恶意/良性,训练任务就是最小化交叉熵损失。
代表方法:
- Flash:两层GraphSage,随后softmax输出01概率
图学习+重建损失异常
训练模型来重建节点或者边特征,例如节点/边的类别、特定节点间是否存在通路等。在检测阶段,如果某处重建误差高于阈值,则认为是可疑节点。
代表方法:
- Kairos:TGN Encoder+MLP Decoder,预测边类型
图学习+嵌入向量库
先嵌入后聚类,例如基于良性数据构建良性行为“基线”。通常要求很好的嵌入质量。
- Magic:图自动编码器+GAT,随机设置一些mask来让模型重建。随后基于良性数据嵌入得到K-D树,预测阶段使用KNN计算异常分数。
社区发现
Kairos采用了louvain社区发现来划分攻击子图,确实可以将时间窗口内一整个大图划分为几个sub_graph,而且效果看起来挺好的。
参考: https://zhuanlan.zhihu.com/p/556291759
社区
在最常见的社交网络中,每个用户相当一个点,用户之间的互相关注、点赞、私信等形成了边,用户以及相互作用关系构成了一个大的关系网络。在这样的网络中,有的用户之间的连接较为紧密,有的用户之间的连接关系较为稀疏。其中连接较为紧密的部分可以被看成一个社区,其内部的节点之间有较为紧密的连接,而在两个社区间则相对连接较为稀疏,整个整体的结构被称为社团结构,如下图,红色的黑色的点集呈现出社区的结构。
模块度
在各类网络中会存在一些紧密连接的区域,这些区域(节点集)通常有自己的属性,称为社群或者社团(Community),社团内部连接紧密,而社团外部的连接则相对稀疏,即“内紧外松”。
“社群检测”等同于“给节点分组”,模块度(Modularity)是一种常用的衡量节点分组质量的标准,模块度越高说明所检测到的社团越符合“内紧外松”的特征,分组质量越好。
模块度最大化算法
该方法的目标是从所有可能的分组中找到使得模块度最大的分组,由于穷举所有可能的分组十分困难,所以实际的算法都采用近似优化方法。例如,Mark Newman 提出了模块度最大化的贪婪算法Fast NewMan (FN)。贪婪算法的原理是找出每个局部最优值,最终将局部最优值整合成整体的近似最优值。