论文阅读 - CASIE: Extracting Cybersecurity Event Information from Text
本文是我在《机器学习》课程上完成的结课作业。 CASIE聚焦于网络安全文本领域的命名实体识别和事件抽取,针对网络安全领域的关注点,对事件和类别做了针对性的特征工程。采用 BIO 标注体系,Bi-LSTM + Attention 作为基础模型,并对比了多种 Embedding 模型对效果的影响,具备很高的实用价值。作者来自马里兰大学,文章发表在 AAAI 2020。
摘要
现有的事件抽取方法主要关注人物相关的信息,这些方法与网络安全事件抽取的核心区别主要有:a) 所需领域专业知识不同;b) 事件本身复杂性不同。本文的主要贡献有:
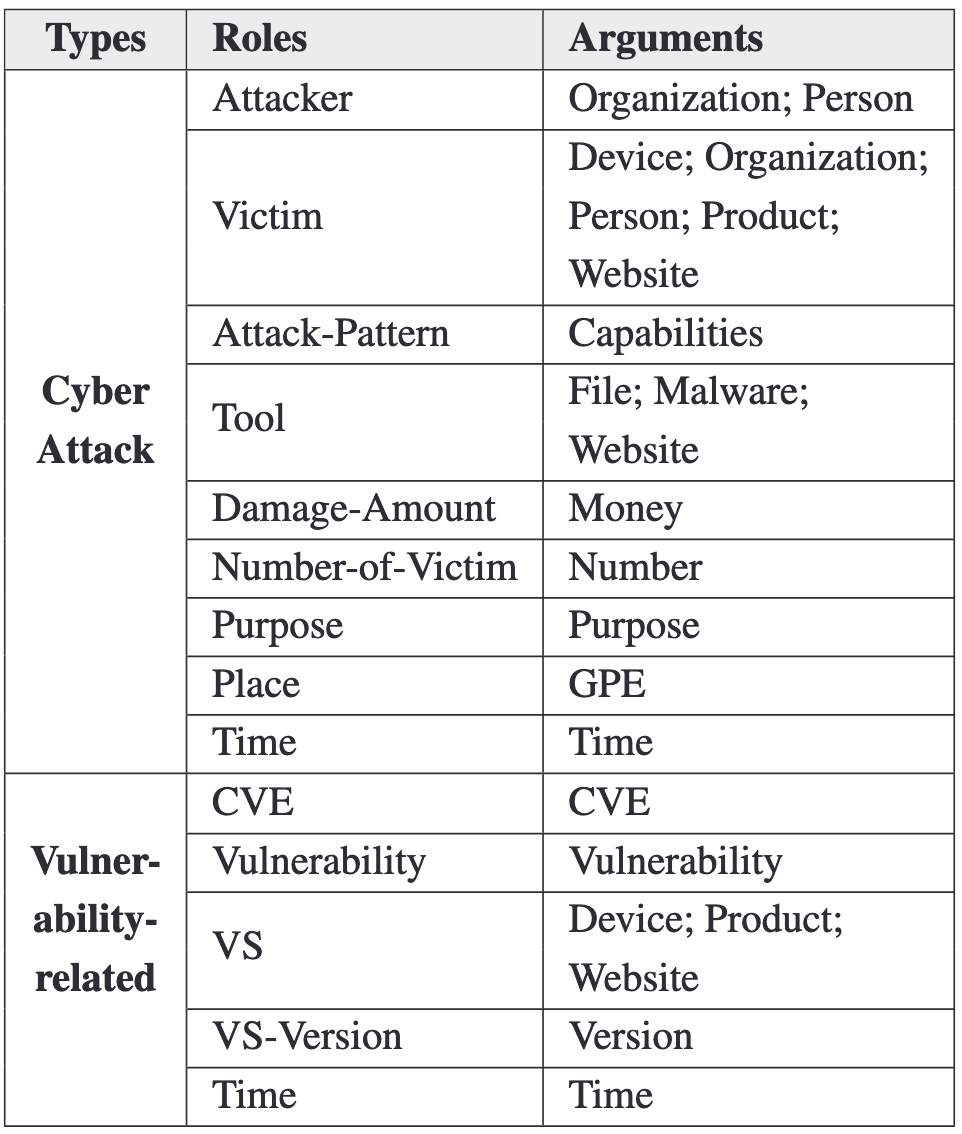
- 定义了五种网络安全事件及其语义角色,以及20种角色参数类型。
- 贡献了一套新闻通讯语料库,对网络安全事件进行了标注。
- 提出 CASIE 网络安全事件信息提取模型和工具。
问题建模
在事件抽取步骤中,定义了如下概念:
- Event Nugget: 事件片段,指清晰描述事件的单词或短语。
- Event Argument: 事件参数,指事件参与者或属性值。
- Role:
Nugget和Argument之间的语义关系。 - Realis: 具有 Actual、Other、Generic 三种取值。
对于攻击和探测事件,定义的子类型有:Attack.Databreach、Attack.Phishing、Attack.Ransom、Discover.Vulnerability、Patch.Vulnerability。
方法
主要包括六个步骤:事件片段识别、事件参数识别、事件参数与角色的关联、事件真实性识别、事件核心参照、映射至知识图谱。本文主要聚焦于前四个步骤。
事件片段及其参数识别(Event Nugget and Event Argument Detection)
特征工程
对于一个 NLP 入门学习者来说,首先需要了解一些前置知识。包括:
- 浅层句法组块(Shallow Syntactic Chunk):指对句子进行分析时,按照一定的语法规则和语义关系将连续的单词组合成的较大的语言单位。例如名词短语(NP)、动词短语(VP)、句子(S)。
- 依赖树( Dependency Tree):表示单词之间的依存关系,例如在句子 “The boy kicks the ball” 中,“kicks” 是核心动词,“The boy” 是动作的执行者(通过 nsubj 依存关系连接),“the ball” 是动作的对象(通过 dobj 依存关系连接)。
在事件片段特征方面,首先使用斯坦福推出的 NLP 工具套件 CoreNLP 对原文进行预处理,包括分词、词形还原、词性标注和命名实体识别、停用词去除。为了更好地涵盖软件名称、恶意软件等实体,还引入了 DBpedia Spotlight 和 Wikidata 两个外部知识库。
在事件参数特征方面,结合了事件片段中的部分特征,并进一步细化和补充。例如确定每个单词的浅层句法组块类型及深度、最近事件类型等特征,使其能够更精准地定位和关联与事件相关的元素,具体特征如下:
- 每个单词的浅层句法组块类型(如 S、NP、VP 等)及其深度(选择分析树中的最低层级)。
- 最近事件的类型(即五种事件类型)。
- 在依赖树中到最近事件核心词的距离(关系跳数)。
- 与最近事件核心词的相对位置(如在同一句子之后、在同一句子之前、在不同句子之后、在不同句子之前)。
- 到最近事件核心词的依存分析路径(如 conj - nmod - nsubj 等)。
- 与最近事件核心词的共同成分分析树节点(如 NP、PP、VP 等)。
词嵌入方法
作者尝试了比较多的 Embedding 方法,并在后续实验中进行了对比,包括:
- 上下文无关性 Embedding:通过不同语料训练的
Word2Vec,包括Transfer-Word2vec、Domain-word2vec、Cyber-Word2vec。 - 上下文相关的 Embedding:
BERT-Base Uncased预训练模型。
值得注意的是,作者并没有直接使用 BERT 原始的输出作为最终的嵌入结果,而是经过实验对比,选择倒数第四个隐藏层的输出作为更优的词嵌入表征。这也是我们值得学习的思路。
模型结构
将各个语义特征的 Embedding 值进行聚合,使用 Bi-LSTM + Attention 提取特征,经过一层带 Dropout 的全连接层后输出,再使用 CRF(条件随机场) 得到 B-I-O 序列标签,具体如下。
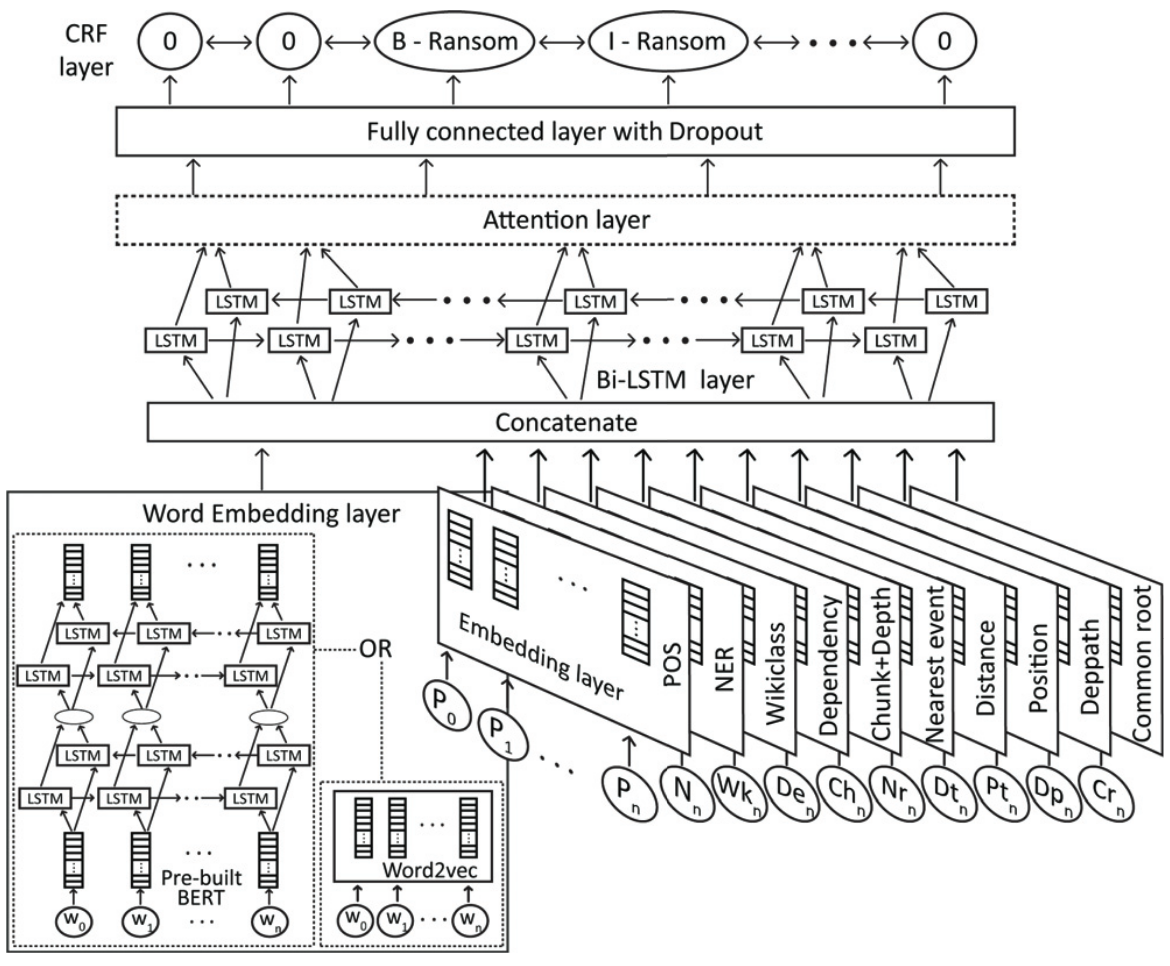
- Embedding Layer:把每个语言特征(包括单词序列,也包括POS、NER、Dependency等特征序列)的嵌入层进行聚合(Concatenate)。对每个特征,输出大小为类别总数的一半。对于单词序列,不同的单词就作为不同类别。
- LSTM Layer:一层 Bi-LSTM 。
- Attention Layer:使用 Location Attention 机制,属于传统 Attention 的变种,引入位置信息来增强注意力权重计算,通常会与内容注意力(Content-based Attention)结合使用,形成 Content-Location Attention。
- CRF层:条件随机场,捕捉标签之间的依赖关系,提高序列标注的准确性。
这里有一个问题,在原文中并没有详细说明如何计算的 Location Attention 分数,在开源的代码来看是调用了 keras 的 SeqSelfAttention,似乎没有体现 Location Attention。但不妨来学习一下,Location Attention 的注意力权重通常可表示为
$$ \alpha_t=Softmax(f_{content}(x_t)+f_{location}(t)) $$
内容注意力比较熟悉:
$$ f_{content}(x_t)=q_t^T k_i $$
位置注意力有多种运算方法,例如位置编码、卷积操作等。使用位置编码时,可表示为:
$$ f_{location}(t) = v^T \cdot p_t $$
其中 $v$ 是可学习的线性变换权重矩阵,$p_t$ 是位置 $t$ 的编码向量。例如在 Transformer 中,位置编码通常使用正弦和余弦函数生成。
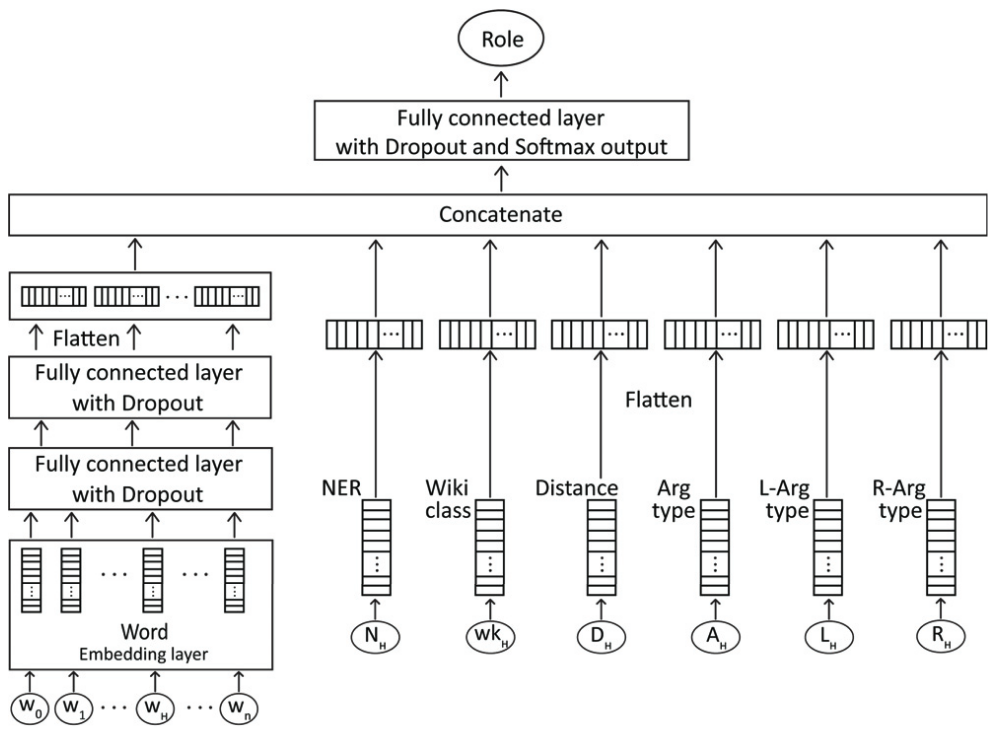
事件参数与角色关联(Event Argument and Role Linking)
为每个事件参数分配一个角色标签,如表1所示。
特征工程
提取以下特征:
- 事件参数表面词的词向量
- 事件片段特征工程的(2)、(3)、(8)项,即 CoreNLP/DBpedia 实体类别、Wikidata 相关类别、关系跳数(hops,取依赖关系树中到最近事件节点头的距离)。
- 目标事件参数类型、目标事件参数的左右侧事件参数类型。
模型结构
包含一个嵌入层和三个全连接层,单词嵌入层经过两个全连接层,然后与其他特征的嵌入层连接。
由于在预测参数角色之前已经知道了事件类型,因此为每种事件建立单独的神经网络,从而排除无关类型。
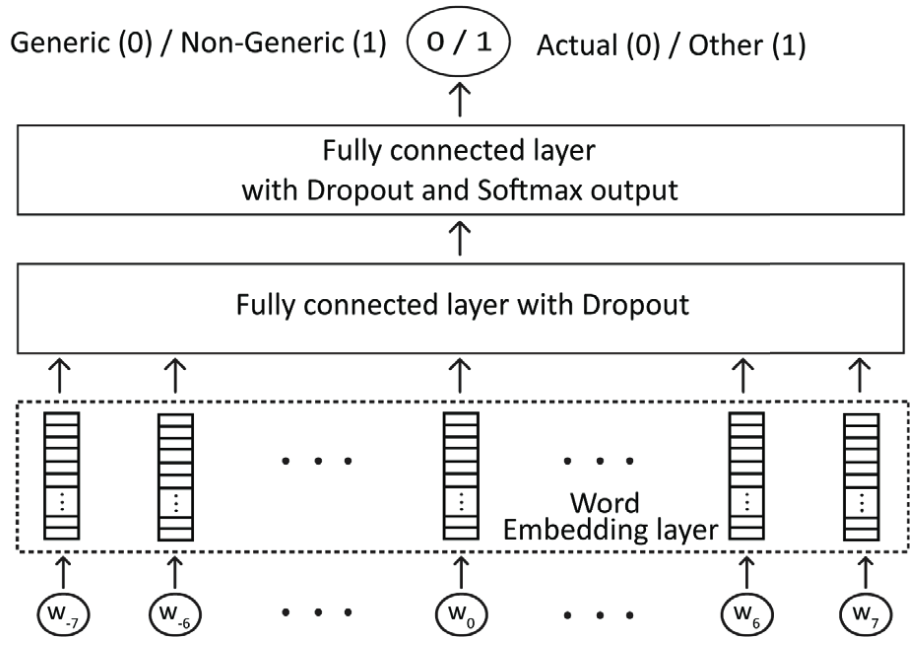
事件真实性识别(Event Realis Identification)
将事件真实性分为 Actual、Other、Generic。当找到事件片段(Nugget)后,realis 特征向量就是 Nugget 及其周围词向量的聚合。实验表明以7个单词为上下文窗口的效果最佳。因情态动词和否定词是事件真实性的重要证据,因此停用词也包含在 realis 识别中。
识别分为两步,首先识别是否为 Generic,若为 Generic 则进一步识别是 Actual 还是 Other。模型结构也较为简单,包括一层 Embedding 和两层全连接层。
数据集及实验
在数据集标注方面,选取了 5000 篇网络安全新闻(Cyberwire 2019),对其中包含文中所提到的五个事件的文章进行人工标注,约 1000 篇。
评估指标
采用为 TAC 事件任务(NIST 2015)开发的指标,通过计算事件要点或参数提及范围与真实范围的重叠来评估。
TAC KBP 2015 包含事件块(Event Nugget)任务和事件论元(Event Argument)任务,与本文一致。通过 Precision、Recall、F1 指标来评估。
交叉验证
使用 900 篇文章进行 8 折交叉验证训练模型,并使用 100 篇文章进行测试,多次运行取平均分数。
消融实验
对 Nugget 和 Argument 检测的特征进行分组,进行消融实验,展示了不同特征集对检测结果的影响。
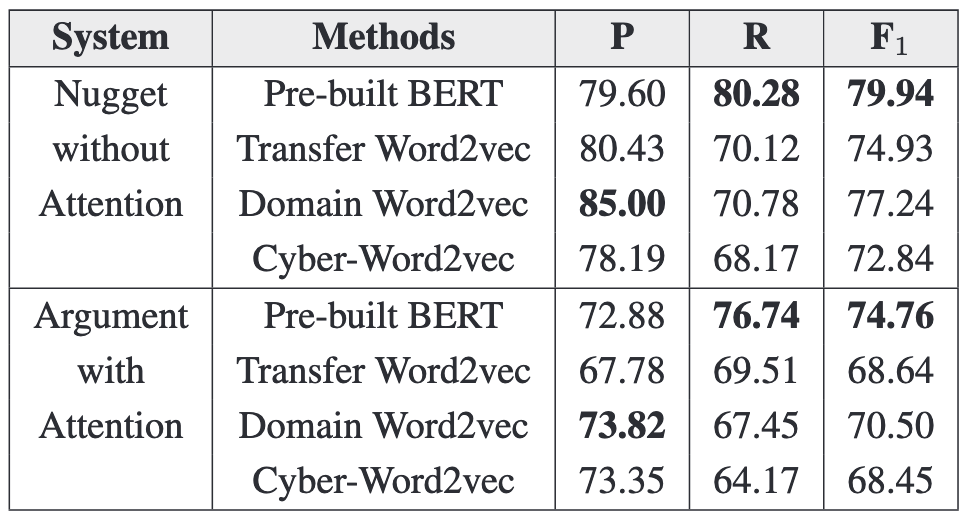
对比多种 Embedding 方法
对预训练的 BERT、Transfer Word2vec、Domain Word2vec、Cyber Word2vec 等不同词嵌入方法进行测试。结果表明,预训练 Bert 多项指标均高于 Word2vec。在 Word2vec 行列,Domain Word2vec 表现最佳。
总结与思考
这篇文章属于深度学习时代的 NLP 典型任务在网络安全领域的应用,尽管在大模型时代来看,其需要额外附加外部知识、精心做特征选择。对我的启发主要有以下:
- 领域针对性设计:传统事件抽取多关注人物相关信息,而本文针对网络安全领域,明确了其与通用领域在专业知识和事件复杂性上的差异,进而定义特定的网络安全事件、语义角色及角色参数类型。
- 分层特征设计:在不同任务步骤(如事件参数与角色关联、事件真实性识别)中,针对具体任务需求,设计与之匹配的特征,这种分层和针对性的特征设计思路,有助于模型在不同子任务中更好地捕捉关键信息。
- 词嵌入方法对比:尝试多种词嵌入方法,并对 Bert 输出层进行选择优化,而不是直接采用 Bert 的最终输出。
- 交叉验证与消融实验:通过8折交叉验证训练模型多次取平均分数,以及对特征分组进行消融实验,增强了实验的完备性。
论文阅读 - CASIE: Extracting Cybersecurity Event Information from Text