论文阅读 - Toolformer: Language Models Can Teach Themselves to Use Tools
本文是我在《自然语言处理》课程上完成的论文阅读作业之一。 Toolformer 聚焦于提升 LLM 通过 API 调用外部工具的能力,提出了 Toolformer。通过对 API 文档和示例的自监督学习,模型可以在问题中有效地决定何时调用、调用何种工具、传入的参数、最优的结果。作者来自 Meta 公司和 Universitat Pompeu Fabra,发表在 NIPS 2023。
原文地址:arxiv/2302.04761
引言
大语言模型尽管在 zero-shot 和 few-shot 问题上有很大提升,但由于模型离线性和自回归本质等因素,其本身存在一些限制,包括:
- 无法获取最新信息
- 存在幻觉现象
- 小规模LM的推理能力欠缺
- 缺乏数学运算能力
- 无法感知时间进程
因此,常用的解决方案是让模型能够调用外部工具,用工具的输出来补充或改写上下文。然而,现有的方法主要有两大不足:依赖人工的大量标注,或者只局限于特定任务中。
读到这里很容易想到
Langchain框架,其也可以轻松地访问外部工具。我们在编写自定义工具时只需在注释中给出工具的简要介绍、参数定义,框架随后在遇到相关问题就会自动选取合适工具并调用。Langchain 应该主要对应提到的第一种不足。
作者认为优秀的 API 工具选择器应具有以下特征:
- 工具选择的学习应该是自监督的,不依赖大量的人工标注。因为人工标注不仅成本高,且人类认为重要的内容不一定是模型认为重要的。
- 外挂工具后,LM 应不丢失其通用性,并且可以自主决定何时、采用何工具。模型应能更全面地使用工具,而不局限于特定任务。
文章最核心的部分,在于提出的自监督数据集的构建方案。首先对数据集中输入文本$x$进行位置划分,对于每个分割点$i$,选出Top $n$个候选 API $C_i^{j}$,随后分别执行得到结果$r_i^j$。分别计算执行结果与next tokens的损失$L_i^j$,若结果表明能降低损失,则保留该候选 API。
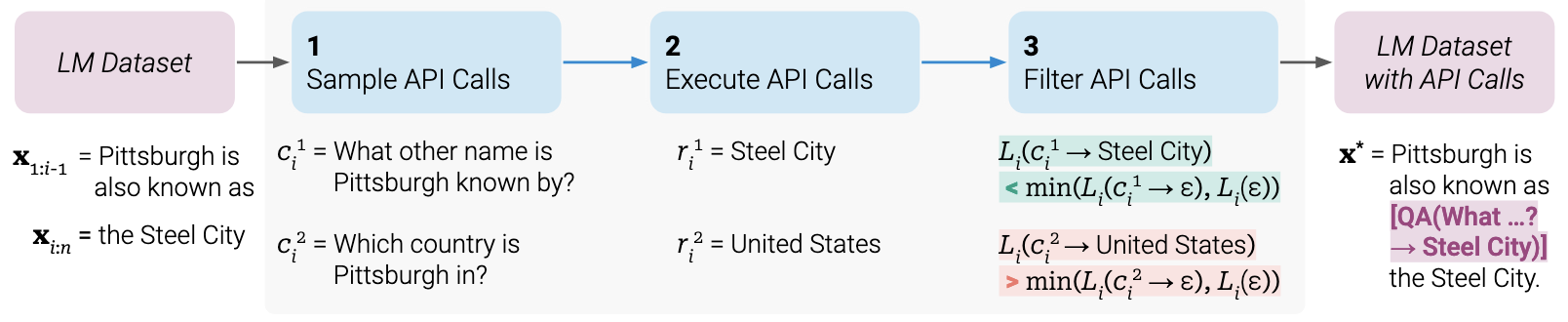
因此,只需要少量人工编写的 API 示例,LM 就可以构造大批工具调用数据集。最后,使用这些数据集微调模型即可。作者在 GPT-J 模型(参数量6.7B)上实验,结果表明大幅提升了模型 zero-shot 能力,在多个任务上超出了规模大很多倍的 GPT-3 模型。
读前问题
在继续阅读论文主体之前,有以下几个问题和思考:
文章提到人工标注工具选择开销较大,那么什么时候才会遇到有大量API需要标注的情况?对于一个实际的大模型,外挂的每个工具 API 应该都需要单独开发的,像 Langchain 那样在 API 编写过程中加入少许提示即可。有没有与 Langchain 的定量对比?
读后回答:没有做这方面实验,文中主要在 GPT-J 上设计对比实验,证明 Toolformer 预训练有效,但未与其他调用工具的方式做对比。
”人类认为有用的提示“和”模型认为有用的提示“有何区别?有没有做这方面实验,如果有的话那对 Prompt 编写会是很好的启示。
读后回答:没有做这方面实验,因为数据集规模比较大(只一个QA问答数据集就接近20k条),人工编写难度大。
框架中分割位置$i$是如何确定的?
读后回答:通过提示工程,给出 Bootstrap Prompt,让模型自己判断。
Next Tokens的loss计算的窗口大小是多少?感觉也会影响到最终效果。
读后回答:是从当前位置$i$一直计算到序列结尾,即从$x_i,…,x_n$。每个位置的损失计算主要考虑在该位置进行 API 调用(有响应或无响应)与不进行 API 调用时模型对后续标记预测的影响,理论上是对每个 API 调用位置独立评估其对模型预测的帮助程度。
因此,感觉当多个 API 调用的结果组合起来才能更好地帮助模型预测时,当前的损失计算方式可能无法完全捕捉到这种复杂关系。
文中方法需要对模型进行 Fine-tune,对比提示工程来说效果怎样?
读后回答:这方面没有作对比。
方法
数据集构建
文中通过自监督实现了 API 调用数据集构建,通过编写一段预提示(Exemplary Prompt,有的论文也叫 Bootstrap Prompt),让 LM 完成 API 调用位置选择,执行选出的 API 拿到结果,随后过滤得到有效的 API 调用。
非常值得学习的是他们评估一个 API 调用是否有效的方法,通过比较加入 API 前后生成序列 Loss 的差异,来定量评估了效果。这比现在大模型工作的许多评估(WinRate、ELo、NLP指标等)更具表现力。此外,他们解决“何时调用”的方案也十分精巧,是直接获取解码序列每个时刻的输出 Top-K,设定开始符号的概率阈值来判断,这是 Langchain 等将模型完全视为黑盒的框架所做不到的。
预提示构建
Exemplary Prompt 如原文 Figure3 所示。
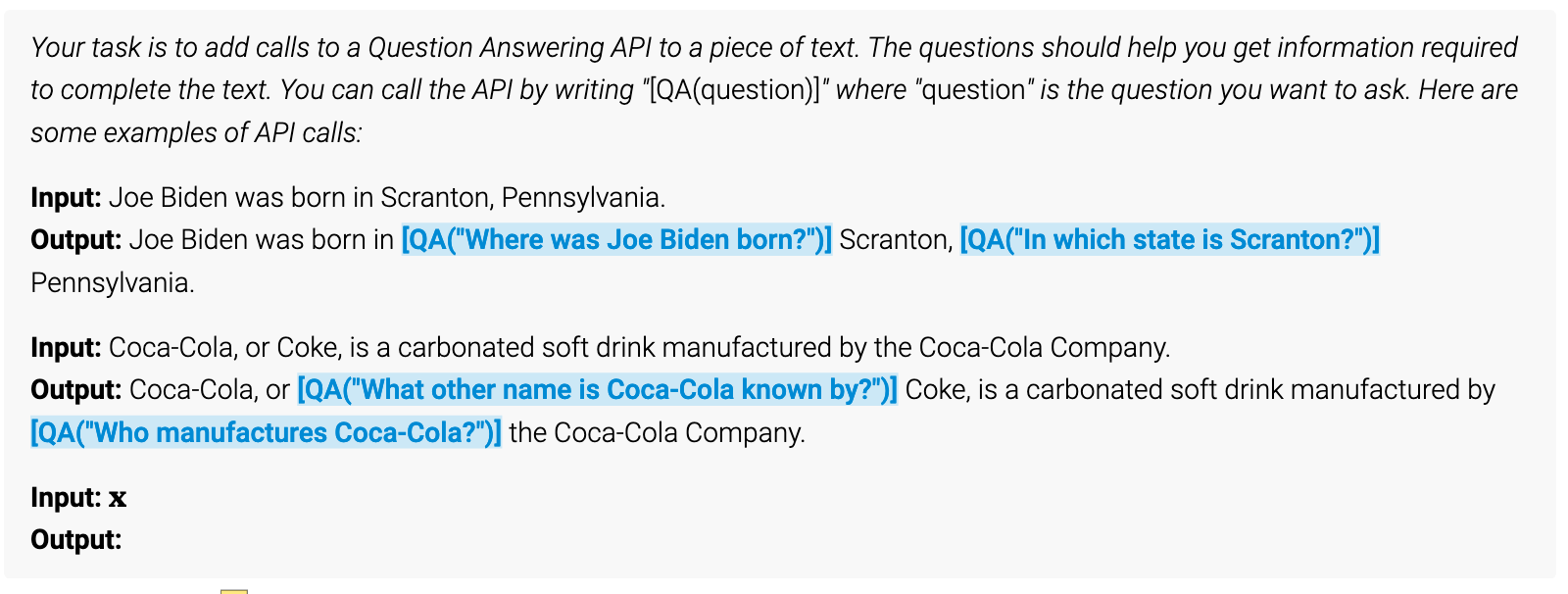
将 API 调用部分以特殊起止Token $\verb|<API>|\space\verb|</API>|$ 包裹。作者为实验可操作性起见,并没有因此而修改词表,而是将起止和结果符号用”[“、”]”、”->” 代替了。这点是我们值得借鉴的。
为了衡量加入 API 后是否对预测有帮助(即损失降低),定义了仅包含 API 调用、包含 API 调用及结果的提示词
$$ e(c) = \verb|<API>| a_c (i_c) \verb|</API>| \space\space e(c,r) = \verb|<API>|a_c(i_c)\rightarrow r \verb|</API>| $$
Sampling API Calls
也就是让模型决定哪里需要进行 API 调用,解决 “When” 的问题。具体步骤是:
- 生成提示(Prompt):对于每个 API ,根据 Exemplary Prompt 编写提示 $P(x)$,以鼓励 LM 在示例输入序列 $x=x_1, … ,x_n$ 中添加 API 调用注释。
- 计算概率:计算模型 $M$ 在每个位置 $i\space (i\in{1, … ,n})$ 开始API调用的概率 $p_i = p_m(\verb|<API>||P(x), x_{1:i-1})$。
- 确定候选位置:设置采样阈值$\tau_s$,保留所有$p_i > \tau_s$的位置 $I={i | p_i > \tau_s}$。如果得到位置超过$k$个,则仅保留前$k$个。
- 采样API调用:对于每个位置$i\in I$,以$[P(x), x1, …, x_{i-1},\verb|<API>|]$为前缀,$\verb|</API>|$为结束标记,形成最多m个 API 候选调用 $c_i^1,…, c_i^m$。
Executing API Calls
执行每个API $c_i$,得到结果$r_i$。
Filtering API Calls
- 计算损失:对于序列 $\textbf{X}=x_1, …, x_n$,有候选 API $c_i$ 及其响应 $r_i$,给定权重序列 $(w_i | i \in \mathbb{N} )$,计算两个加权损失 $L_i^+$ 和 $L_i^-$。简单来说,前者为加入 API 调用及其结果后的损失,后者为不进行 API 调用和进行 API 调用但不提供响应这两种情况下损失的最小值。直观上,如果$L_i^-$较大而$L_i^+$较小,说明进行 API 调用后更有帮助。
- 筛选有用的API调用:给定阈值$\tau_f$,保留$L_i^- - L_i^+ \geq \tau_f$的调用。
模型微调
对构建的数据集进行微调,只对需要的位置进行 API 调用序列的插入,而不改变其他内容,以此保持模型的通用性。
模型推理
当解码时遇到$\rightarrow$ Token 时(即”->”),暂停输出,调用对应 API ,并将结果加入到解码序列中,继续完成解码。
实验部分
作者主要进行了三方面的实验:一是测试提出的 API 调用选择方法是否在下游任务中真正有效;二是验证该方法不会损害 LM 本身的核心能力;三是测试不同规模的模型对工具调用的影响。
选用工具
在挑选所使用的工具时,遵循两个原则:一是输入输出都可以用文本表示,二是可以获知他们用途的一些演示。因此,作者选用了问答系统、维基百科搜索、计算器、日历、机器翻译系统这几类 API 来做测试。
实验场景
数据集选用 CCNet 子集 $\mathcal{C}$。CCNet 他是一个从网络抓取数据中提取高质量单语数据集,发表在 LREC 会议上:CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data。作者采用“启发式”方法创建了 CCNet 子集,例如判断文本中是否包含三个操作数,来决定是否保留作为 Calculator 任务的数据集,从而大幅缩减数据量。
模型选用 GPT-J,是一个基于 GPT-3 的具备6B参数量的模型。截止2022年,它是目前公开可用的Transformer语言模型中,在各种下游zero-shot任务上表现最好的。Hugging Face: GPT-J 6B。文章还选用了规模大许多倍的 OPT(66B)和 GPT-3(175B)模型,来验证模型大小对工具调用的影响。
参数方面,设定权重函数 $w_t$,来确保 API 调用发生在 API 提供的信息对模型实际有帮助的位置附近。对于 API 的采样阈值 $\tau_s$和筛选阈值 $\tau_f$,每个工具是独立选择的,可见原文 Table 2。
对比实验做了三个场景:
- GPT-J + CC:用 CCNet 子集 $\mathcal{C}$ 微调的 GPT-J。
- Toolformer Enabled:用文中方法制作的数据集 $\mathcal{C}^*$微调 的 GPT-J。
- Toolformer Disabled:使用2中所得模型,但解码时屏蔽所有 API Call。这是通过手工将每个位置解码输出中 $\verb|<API>|$ Token 的概率改为0实现的。
这里设计的3个对比场景值得学习。不难看出,1和2对比主要是为了证明在微调过程中引入 API 调用是否能提升模型的性能,即模型是否能学习到在合适的时机调用合适的工具来辅助处理任务。2和3对比主要是证明调用 API 之后是否真正能提高模型解决问题的能力,进一步验证使用工具的必要性。
在模型解码方面,采用贪婪解码,当 Top-10 Token中包含 $\verb|<API>|$ 时则直接选用 $\verb|<API>|$。
效果评估
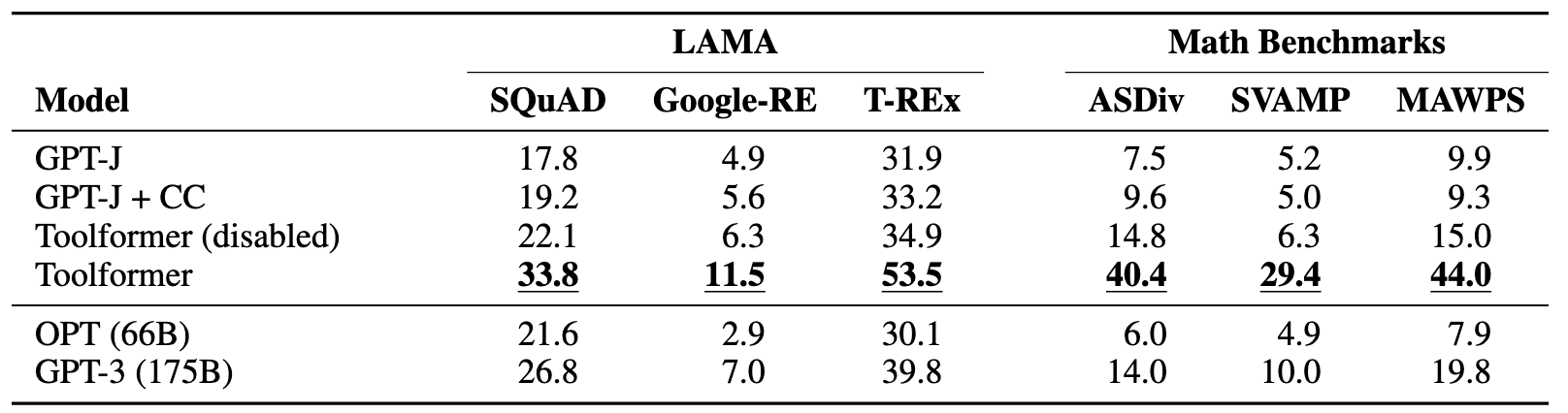
通用知识评估:使用
LAMA Benchmark的 SQuAD, Google-RE, T-REx 三套数据集来评估,用来检测语言模型中包含了多少的事实类与常识类的知识。值得注意的是,由于 LAMA 基于直接从 Wikipedia 获取的语句,作者阻止了 Toolformer 使用 Wikipedia API,以避免获得不公平的优势。数学能力评估:使用
Math Benchmarks来评估,这是UC Berkeley提出的一个用于评估机器学习模型的数学问题解决能力的数据集。
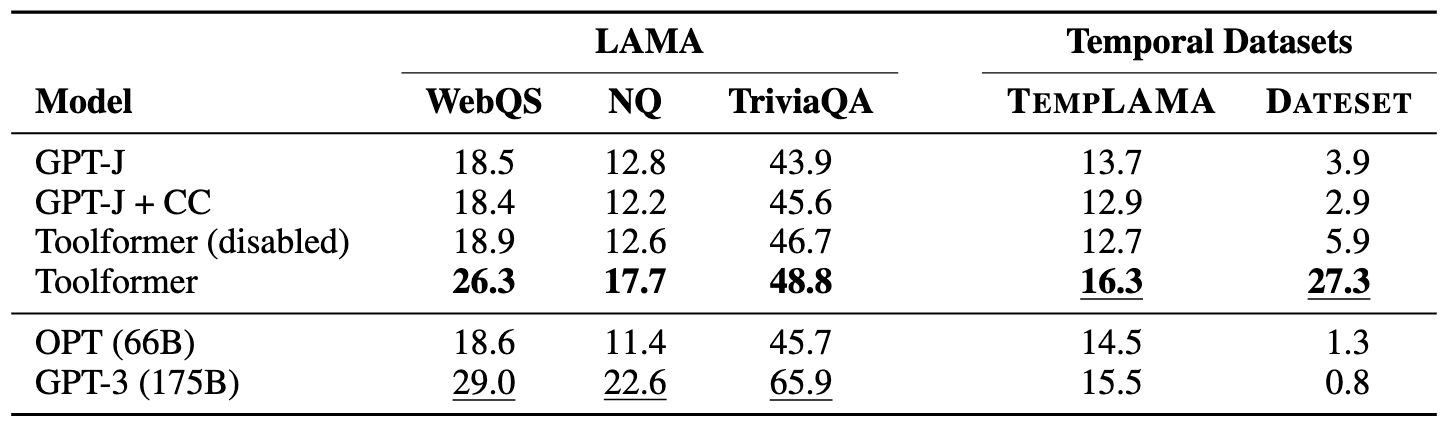
问答能力评估:使用
LAMA Benchmark的 WebQS、NQ、TriviaQA 三套数据集来评估。在一系列对比中,Toolformer 的成绩仅比 GPT-3 略低一筹。同时,还使用带有时间的数据集来评估其时间进程方面的能力,这一点超过了 GPT-3。
多语种问答:使用
MLQA来评估多语种问答能力,即上下文以英文表示,而问题是其他语种(包括中文)。结果表明在某些语言上,使用Toolformer会使效果变差。但是每种语言的 Toolformer(disabled) 都比 Toolformer 低,说明 API 调用是有用的,作者认为表明它已经学会使用机器翻译工具。另外,作者认为OPT和GPT-3多语言能力较低的原因是没在多语言数据集上训练。最下面两组 All En 的测试证明了这一点。
汇总结果如下,证明了 a. 调用工具API确实对提升问题解决能力有效; b. 使用 Toolformer 预训练的小规模模型在后续 Zero-shot 方面能力超过大模型 GPT-3。
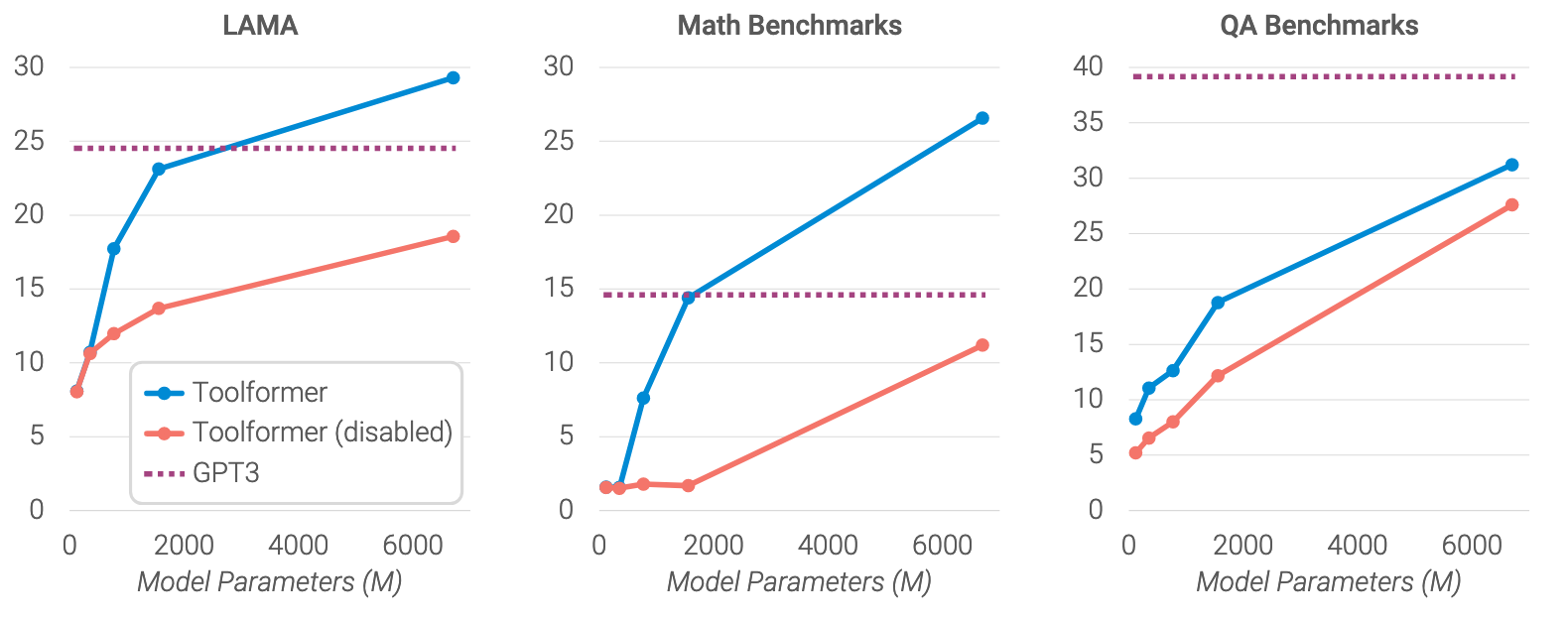
至此,文章完成了对于第一个方面的实验,即 Toolformer 方法有效提升了模型在下游任务中的能力。
对于是否会损害模型本身建模能力、不同规模模型对工具调用的影响,作者在4.3和4.4小节做了简要描述,结论如下:
- 对模型训练的困惑度进行评估,表明 Toolformer 对模型本身建模能力影响不大。
- 提供工具的能力在约 775M 参数时才出现,较小模型使用和不使用工具性能相似。
- 模型规模增大时,不使用 API 调用解决任务的能力变好,同时利用 API 的能力也提高,但即使最大模型,使用和不使用 API 调用的预测之间仍有较大差距。
局限性
作者提到一个明显的局限是无法链式调用工具,因为每个 API Call 位置都是独立生成的。这点很好的解答了读前的问题4。同时,数据集生成的效率比较低,因为需要对每个文档单独进行提示工程推理,例如处理一百万份文档后,只能得到几千个有用的计算器 API 调用示例。最后,当前的 Toolformer 并未将调用 API 的成本纳入考虑。
总结与思考
这篇文章我认为启发有以下几点:
- 方法方面,结合提示工程设计了自监督的训练方案,使其可以用简单的 Loss 作为监督条件,来生成 Fine-tune 所用的数据集。在许多大模型 Fine-tune 的文章中,数据集生成是一个痛点,人工标注代价太大,而使用第三方大模型生成又无法保障质量。
- 技巧方面,对开源大模型的 Decoding 原始输出进行了利用和改造,没有将其完全作为黑盒来 Fine-tune。
- 评估方案方面,精巧的设计了几个对比实验,有力地证明了方法有效性。同时,还对方法本身之外的两个问题(是否导致困惑度增大、LM 规模与工具调用能力的关系)进行了测试,使结论更加充实。
同时,关于本工作我还有自己的几点思考:
- 该方案本身无法实现链式的工具调用,若想基于它实现的话,感觉可以尝试通过多轮对话的方式形成多个 API 调用点,从而构成简单的 CoT。
- 该方案需要对 LM 进行微调,使其获得选择 API 的能力。若模型规模特别大,微调将花费较大的时间和成本。除了使用更精简的微调技术外,感觉可以尝试大小模型协作的方案,例如使用提示工程让大模型初步分析可能的 API 调用位置,再让 Toolformer 小模型进行更精细的 API 调用决策和参数调整。
- 很希望将这个方法与纯 Prompt方式的(例如langchain)工具框架进行对比,看看哪种方式更有效。
论文阅读 - Toolformer: Language Models Can Teach Themselves to Use Tools