Docker 常识查漏补缺
Docker是一种轻量级的虚拟化技术,同时是一个开源的应用容器运行环境搭建平台。其解决了环境差异、依赖关系管理和部署一致性等问题,已经成为极为流行的技术。云原生技术的兴起,进一步强调了它的重要性。
笔者没有系统的学习过Docker,但日常却完全离不开Docker。在近期的几个项目中,发现了自己在这方面的诸多薄弱点,故回顾如下。
1. pid与进程隔离
问题出现
我意识到这个问题,是源于一次elasticsearch的使用。我在宿主机中安装了es,但现在需要另一个版本的es,为方便安装,就用docker启动了一个。
时隔多日,我忘记了自己在docker中还启动了一个es服务。当需要kill掉它们时,却发现kill -9 {pid}后,会自动重启。在宿主机上ls这个目录,也找不到对应的文件。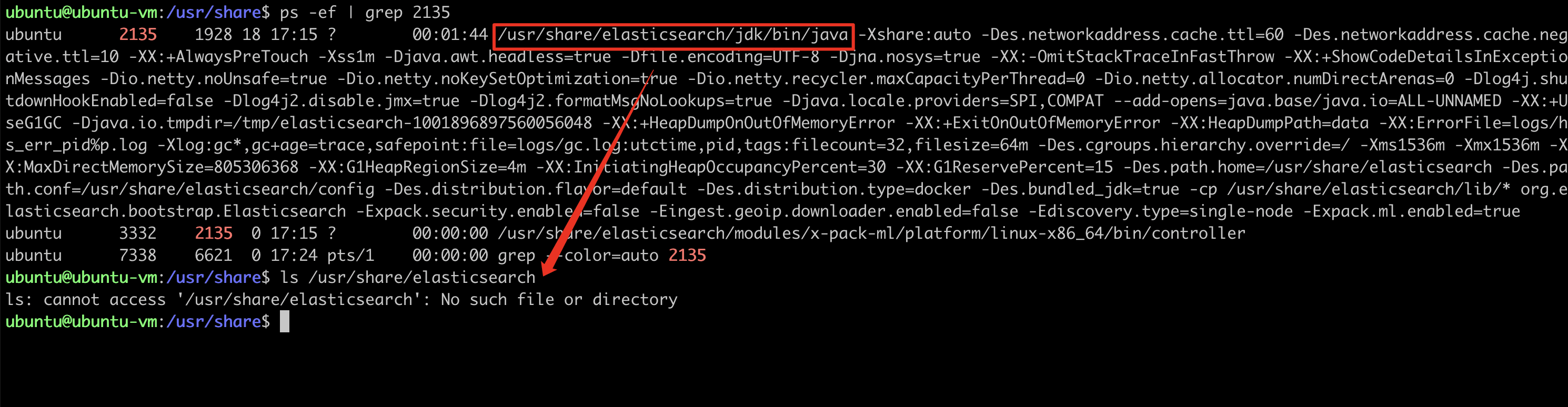
最后才想起来是自己Docker启动的es,令好友也倍感诧异…
甚至在Docker官方社区中,我们也能看到这样的讨论:
其实,在宿主机中使用ps/htop等命令能看见Docker进程是正常的。这是由于Docker 是基于 Linux 内核的 Namespace 技术实现资源隔离的,所有的容器都共享主机的内核。
什么是Namespace
Namespace 是 Linux 内核的一项功能,该功能对内核资源进行分区,以使一组进程看到一组资源,而另一组进程看到另一组资源。Namespace 的工作方式通过为一组资源和进程设置相同的 Namespace 而起作用,但是这些 Namespace 引用了不同的资源。资源可能存在于多个 Namespace 中。这些资源可以是进程 ID、主机名、用户 ID、文件名、与网络访问相关的名称和进程间通信。
简单来说,Namespace 是 Linux 内核的一个特性,该特性可以实现在同一主机系统中,对进程 ID、主机名、用户 ID、文件名、网络和进程间通信等资源的隔离。Docker 利用 Linux 内核的 Namespace 特性,实现了每个容器的资源相互隔离,从而保证容器内部只能访问到自己 Namespace 的资源。
Linux中定义了6种Namespace:
| Namespace | 作用 | 描述 |
|---|---|---|
| Mount | 隔离文件系统挂载点 | 每个namespace都可以有不同的文件系统视图 |
| PID | 隔离进程ID | 每个namespace可以有自己的进程空间,使得一个进程在不同namespace中可以有不同的PID |
| Network | 隔离网络设备 | 每个namespace拥有自己的网络设备、IP地址、路由表等 |
| IPC | 隔离System V IPC和POSIX message queues | 每个namespace有自己的IPC资源 |
| UTS | 隔离主机名和域名 | 每个namespace可以有自己的主机名和域名 |
| User | 隔离用户ID和组ID | 每个namespace有自己的用户和用户组,使得在namespace内部,一个用户可以被视为root用户,而在namespace外部,该用户只是普通用户 |
Docker中对Namespace的使用
在宿主机上,可以观察到Docker 守护进程为每个容器创建了六种 namespace 的实例,并且由内核管理这种映射关系。
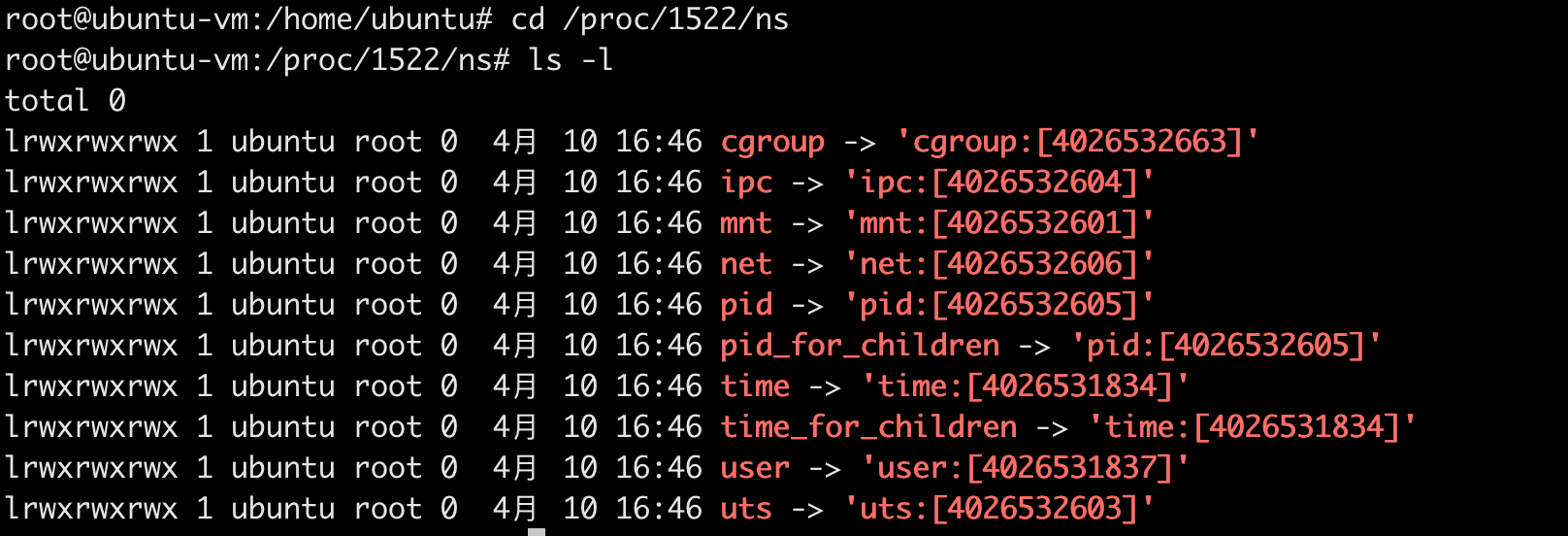
那么,这种映射关系是由谁创建的呢?Docker 的运行时组件(如 containerd、runc 等)负责创建和管理容器,在创建容器时会配置 PID namespace。
Cgroups
Namespace提供了资源隔离,而Cgroup则可以说是提供了资源管理。
Linux Cgroup 可让为系统中所运行任务(进程)的用户定义组群分配资源 -–— 比如 CPU 时间、系统内存、网络带宽或者这些资源的组合。 您可以监控您配置的 cgroup,拒绝 cgroup 访问某些资源,甚至在运行的系统中动态配置您的 cgroup。 所以,可以将 controll groups 理解为 controller (system resource) (for) (process) groups,也就是是说它以一组进程为目标进行系统资源分配和控制。
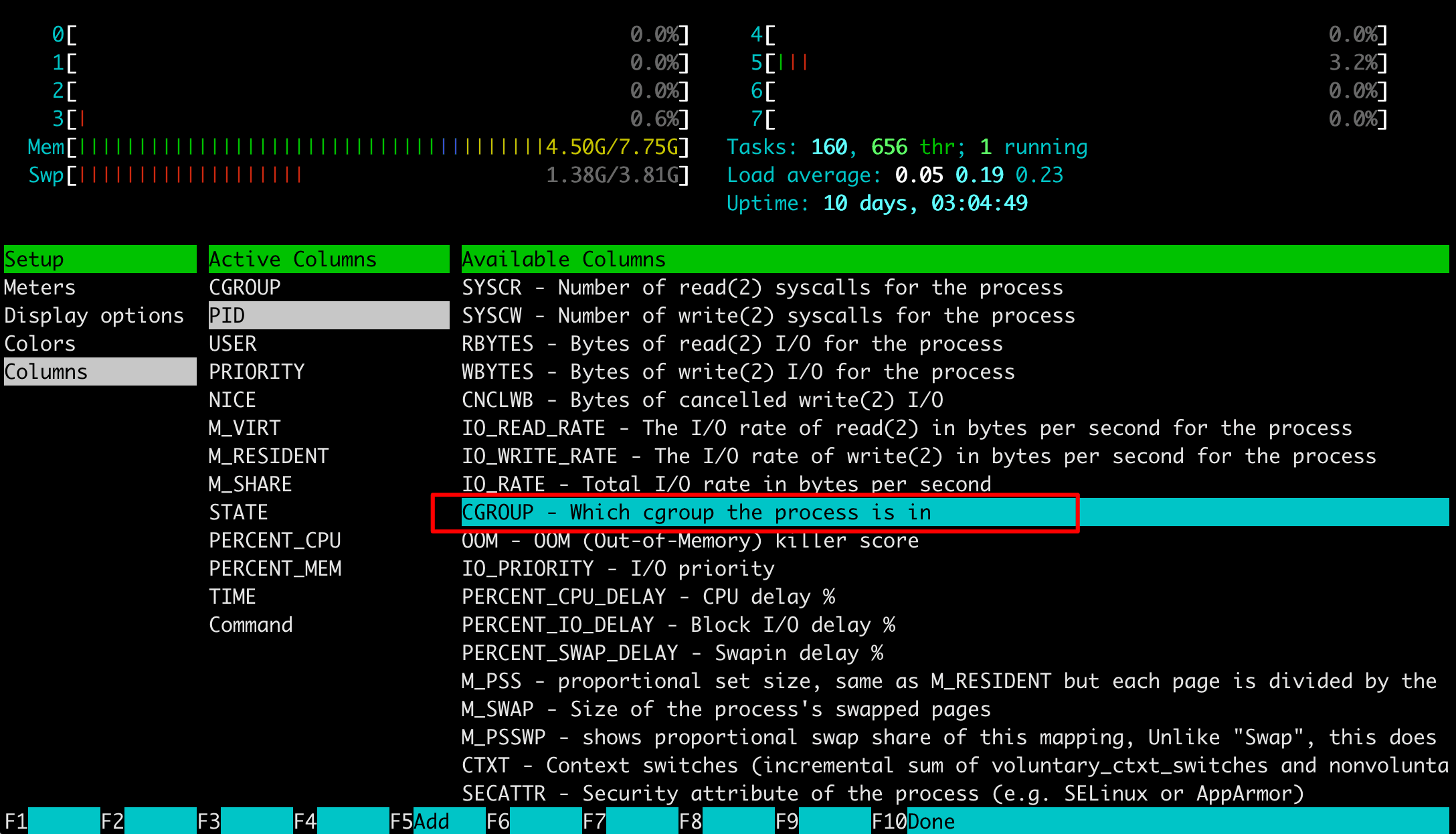
宿主机htop中排除Docker容器进程
有了上述基础,实际上我们只需要排除指定的Cgroups就可以。
不妨按F2设置显示CGROUP名称,再F4即可。

2. 网络代理问题
Docker pull代理
在执行docker pull时,如果网络环境较为复杂,我通常通过终端代理命令(例如export https_proxy=http://127.0.0.1:1234)来试图让pull过程走代理,实际上这是没有用的。
在执行docker pull时,是由守护进程dockerd来执行。因此,代理需要配在dockerd的环境中。而这个环境,则是受systemd所管控,因此实际是systemd的配置。
1 | sudo mkdir -p /etc/systemd/system/docker.service.d |
在这个proxy.conf文件(可以是任意*.conf的形式)中,添加以下内容:
1 | [Service] |
dockerd 代理的修改比较特殊,它实际上是改 systemd 的配置,因此需要重载 systemd 并重启 dockerd 才能生效。
容器内代理
在容器运行阶段,如果需要代理上网,则需要配置 ~/.docker/config.json。以下配置,只在Docker 17.07及以上版本生效。
1 | { |
此外,容器的网络代理也可以直接在其运行时通过 -e 注入 http_proxy 等环境变量。这两种方法分别适合不同场景。config.json 非常方便,默认在所有配置修改后启动的容器生效,适合个人开发环境。在CI/CD的自动构建环境、或者实际上线运行的环境中,这种方法就不太合适,用 -e 注入这种显式配置会更好,减轻对构建、部署环境的依赖。当然,在这些环境中,最好用良好的设计避免配置代理上网。
Build代理
虽然 docker build 的本质,也是启动一个容器,但是环境会略有不同,用户级配置无效。在构建时,需要注入 http_proxy 等参数。
1 | docker build . \ |
参考来源:
https://cizixs.com/2017/08/29/linux-namespace/
https://developer.aliyun.com/article/1406336
https://blog.csdn.net/vic_qxz/article/details/130061661
Docker 常识查漏补缺